--[ Experimento 0x02: Buscando Seeker ]--
Inteligencia de amenazas
Por: ZoqueLabsEste escrito se distribuye con una licencia Creative Commons CC BY-SA (Reconocimiento - Compartir Igual). Fue realizado con el apoyo de Derechos Digitales.
English version
-[ ToC ]-
-> 0x00 Intro -> 0x01 Entendiendo Seeker -> 0x02 OpSec -> 0x03 A la caza (favicons primero) -> 0x04 Documentar hallazgos en Colander -> 0x05 Exportar Feeds y usarlos como IOCs en MVT -> 0x06 Esto es solo el comienzo.
–[ 0x00 Intro ]–
¡Saludos, gente!
En ZoqueLabs nos encanta la inteligencia de amenazas, y este es nuestro primer write-up sobre el tema. Después de meternos a fondo en las tripas de Android, cambiamos de aire para oler un poco de TCP/IP y arrancar un experimento básico pero potente: aprender a buscar y rastrear infraestructura maliciosa.
El punto de partida fue este artículo: Seeker: How a Simple Link Can Reveal Your Smartphone’s Location. A partir de ahí planteamos el objetivo: encontrar instancias de Seeker, documentarlas y generar indicadores de compromiso reutilizables y compartibles.
Primero jugamos con Seeker (ya explicaremos qué es y cómo funciona) usando servidores temporales y gratuitos de segfault —un servicio de The Hackers Choice— y, de paso, aprendimos a usar esos mismos servidores como proxies para asomarnos con más seguridad a la infraestructura que íbamos hallando. Todo ese recorrido está documentado aquí, con una sección dedicada a OpSec aplicable a este y a muchos otros casos en los que haya que tocar infraestructura maliciosa.
La cacería la hicimos con Censys y Shodan (versiones gratuitas). Piensa en Google, pero en vez de páginas, devuelven metadatos que delatan servicios y dispositivos conectados: justo lo que necesitamos para perfilar objetivos.
Claro: detectar no alcanza si no podemos compartir. Por eso organizamos, clasificamos y normalizamos la información para que sirva a organizaciones hermanas. Con la experiencia previa en Colander —software libre para gestión de casos—, montamos el caso y aprovechamos funciones que nos ayudan a convertir datos en inteligencia accionable. Además, activamos feeds para exportar reglas STIX2 que luego pueden consumirse en MVT.
Este escrito viene cargado: herramientas de hackeo, rastreo de infraestructura, VMs efímeras, túneles, proxies, IOCs, Colander, MVT, OpSec y, sí, ¡todo al gratín! Así que vayan limpiando sus terminales: las vamos a ensuciar. ¡Vamos!
–[ 0x01 Entendiendo Seeker ]–
0x01.1 Lo básico
Seeker es una herramienta que usa las APIs del navegador para extraer ubicación precisa y otros datos del dispositivo. Fue creada para realizar geolocation phishing, es decir, engañar a un objetivo para que comparta su ubicación real a través del navegador. Pero eso no es todo, también recolecta metadatos del dispositivo, como modelo, resolución de pantalla, sistema operativo, red y más. No instala nada, no explota vulnerabilidades, no se mete con el sistema operativo. Solo espera a que la víctima entre a un enlace y le dé permiso al navegador para compartir la ubicación. Con eso, Seeker hace su trabajo.
A nivel técnico, Seeker levanta un servidor web que sirve una página personalizada (tipo Google Drive, grupos de Telegram, Whatsapp..). Esa página incluye un script en JavaScript que pide acceso a la ubicación usando la API de geolocalización de HTML5. Cuando el navegador lo permite, Seeker captura:
- Coordenadas GPS (latitud, longitud)
- Precisión (en metros)
- IP pública
- Detalles del sistema: navegador, sistema operativo, resolución, etc.
Luego, en la mayoría de los casos, seeker redirecciona a la víctima a una página legítima, procurando así, pasar desapercibido.
Todo se almacena y se muestra en tiempo real desde la terminal. Sin embargo, en nuestra investigación, nos fijamos que incluso si el navegador por default le niega la geolocalización a Seeker, este igual recolecta información sensble como: IP pública, navegador, sistema operativo, tipo de dispositivo, etc. A esto nos referimos cuando hablamos de mantener un buen opsec durante la búsqueda, para no entregar información que nos pueda identificar.
Y acá es donde Seeker se vuelve relevante: es simple y funciona, y eso basta para demostrar que la ingeniería social sigue siendo efectiva. Sabemos que muchas campañas maliciosas, especialmente en América Latina, usan tácticas muy parecidas: un enlace, una web clonada, y el navegador haciendo el resto. Aprender cómo opera Seeker permite ver el ataque desde adentro, entender cómo se mueve, reproducirlo en entornos controlados y empezar a reconocer patrones que podrían pasar desapercibidos en un primer análisis. Ten presente que en los logs si sale la informacion completa del navegador.
Bueno sin más preambulo, ahora si vamos a correr Seeker.
0x01.2 Correr Seeker
Antes de correrlo, recomendamos hacerlo siempre desde un entorno controlado: una máquina virtual, un contenedor o una infraestructura aislada. No solo por seguridad, sino para evitar filtrar info sin querer. Nosotrxs decidimos usar uno de los servidores temporales y gratuitos de segfault de The Hackers Choice.
0x01.2.1 Segfault
Segfault es un servicio de servidores temporales efímeros: máquinas Linux que puedes levantar con un solo comando y que desaparecen al cabo de unos dias. Son perfectas para pruebas rápidas, experimentos controlados y —como en este caso— correr herramientas sin ensuciar tu propio equipo.
Lo interesante es que no necesitas crear cuentas ni registrar nada. Un solo comando vía ssh te da acceso inmediato a un servidor con red pública. Eso significa que puedes usarlo como espacio de pruebas, como puente (proxy) o incluso como punto de salida para túneles reversos.
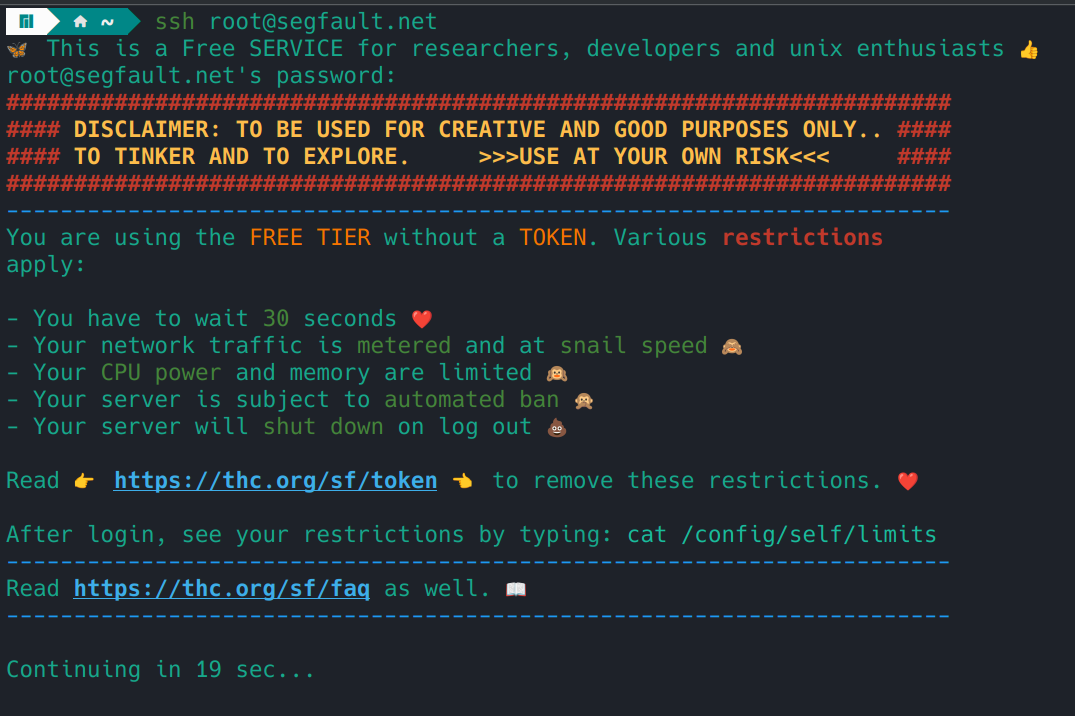
ssh root@segfault.net
Por defecto, estas máquinas mueren solas después de un tiempo. Pero hay un truco: puedes guardar tus credenciales de acceso (la clave SSH que se genera la primera vez) y, si vuelves a conectarte antes de 72 horas, tu sesión sigue activa. Esto te permite retomar experimentos sin empezar desde cero, siempre que no dejes pasar demasiado tiempo.
Cuando finalmente cae, simplemente levantas otra y ya esta.
0x01.2.2 Tmux - mantener vivo a Seeker
tmux es un multiplexor de bolsillo, es lo que evita que pierdas todo cuando el SSH se cae. Imaginemos a tmux como varias pantallas dentro de una sola conexión: Seeker en una, túnel en otra, pruebas y logs en otra. Si la conexión se rompe, la sesión sigue viva y puedes volver a conectarte. Aquí lo usamos para:
- Panel 1: Corre Seeker y evita que muera si perdemos la conexión.
- Panel 2: el túnel HTTPS
Comandos básicos que usamos:
tmux new -s seeker # crear sesión 'seeker'
# dentro de tmux:
# dividir horizontal: Ctrl-b "
# dividir vertical: Ctrl-b %
# mover entre paneles: Ctrl-b o
Ctrl-b d # detach
tmux attach -t seeker # reconectar
Esto nos dio la tranquilidad de que, aunque se cortara el SSH, Seeker seguiría corriendo. Solo era cuestión de volver a conectar y hacer tmux attach.
0x01.3 Iniciando Seeker — paso a paso dentro de segfault + tmux
Con todo esto listo ahora si a lo que vinimos vamos.
- Clonar el repo: Dentro de segfault vamos a instalar seeker desde el repositorio oficial en github, con el siguiente comando:
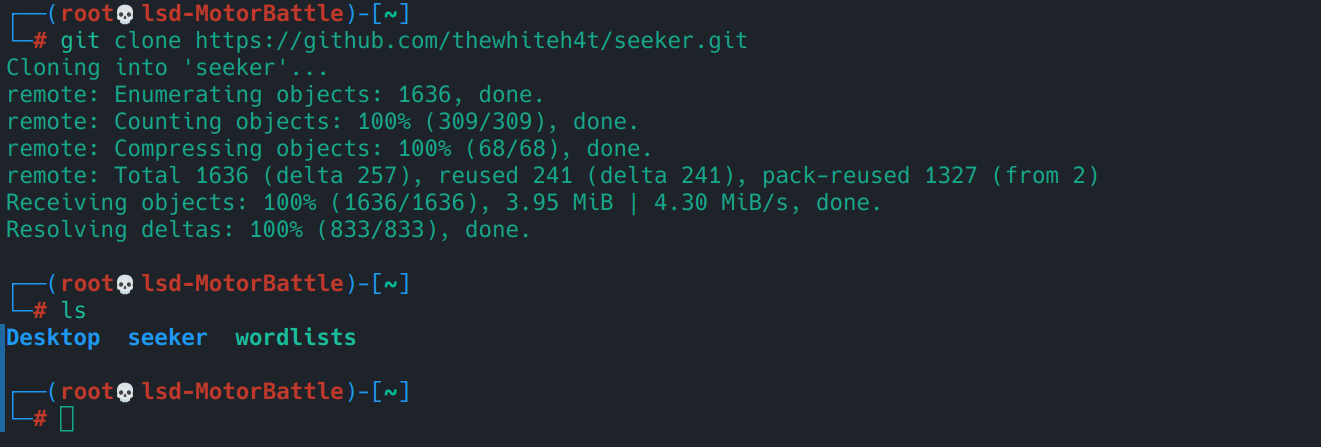
git clone https://github.com/thewhiteh4t/seeker.git
Debería verse así:
─(root💀lsd-LizardSoft)-[~]
└─# git clone https://github.com/thewhiteh4t/seeker.git
Cloning into 'seeker'...
remote: Enumerating objects: 1636, done.
remote: Counting objects: 100% (312/312), done.
remote: Compressing objects: 100% (63/63), done.
remote: Total 1636 (delta 266), reused 249 (delta 249), pack-reused 1324 (from 2)
Receiving objects: 100% (1636/1636), 3.95 MiB | 3.10 MiB/s, done.
Resolving deltas: 100% (836/836), done.
Es posible que no te deje instalar si no has preparado la VM en segfault, si quieres puedes pasarle antes el
apt update,apt install python3 python3-pip curlpara que no te bote errores.
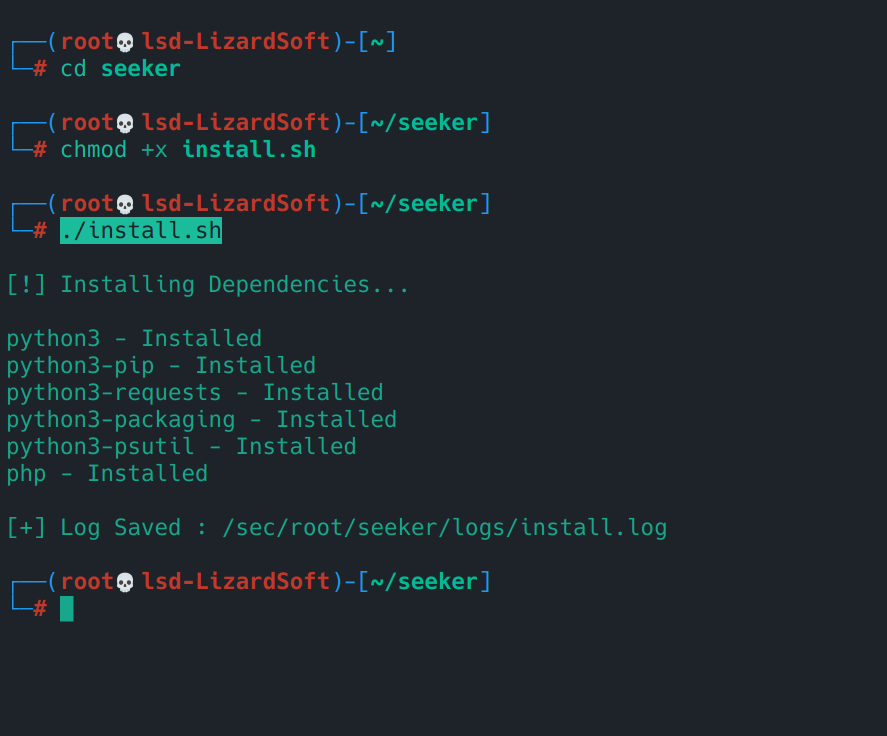
- Ahora, ve al path donde está Seeker y lo instalas en la VM así:
cd seeker
chmod +x install.sh
./install.sh
- Bien ahí. Ahora vamos a correr seeker desde la ventada de
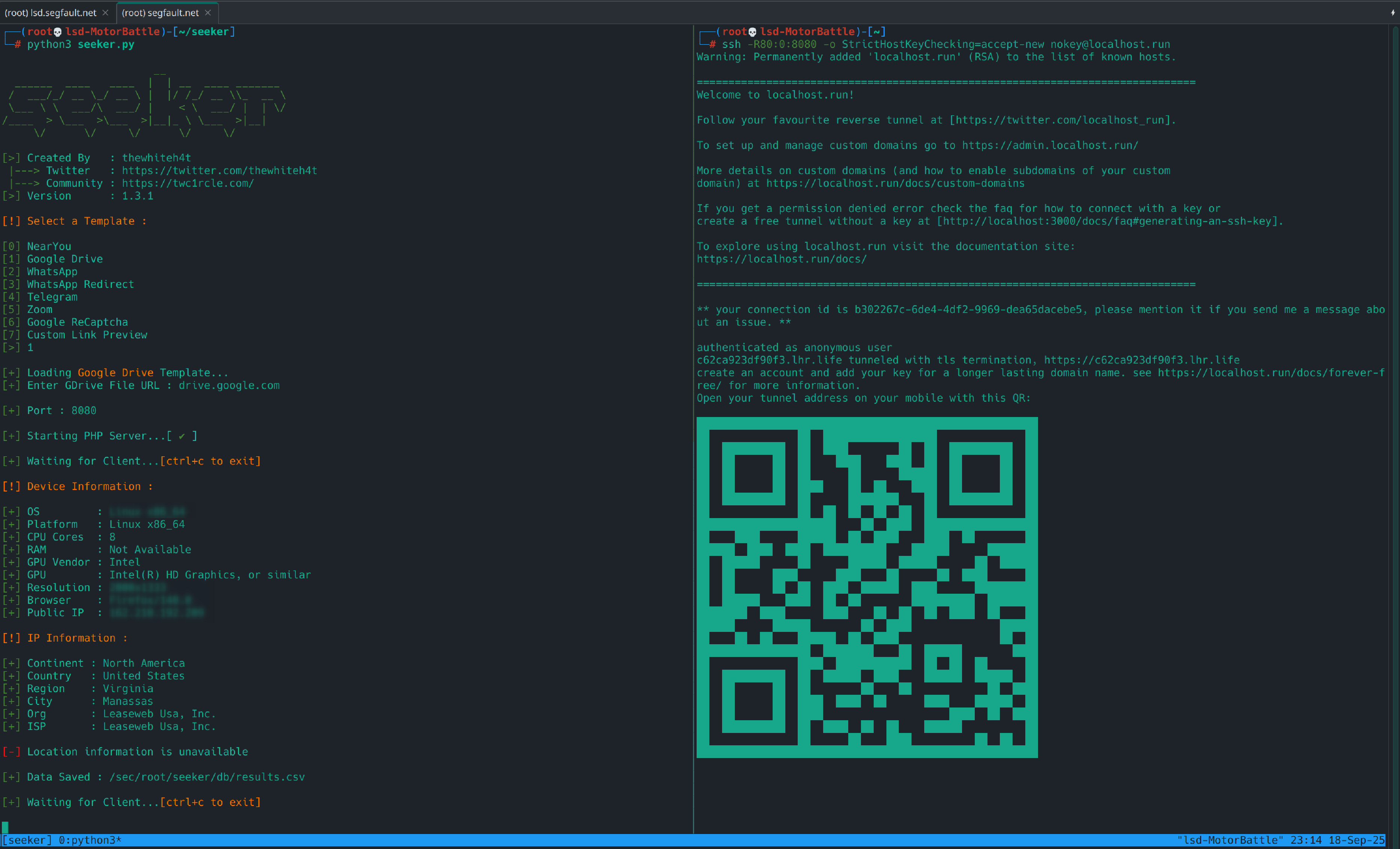
tmux.tmux new -s seekerYa acá dentro corremos seeker con:
python3 seeker.py
Aquí puedes seleccionar alguna opción: Google drive, Near You, WhatsApp, Telegram, etc. estos son los templates que tiene Seeker por defecto, la idea es probarlos y recolecctar información. Cuando escogemos un template nos pedirá algunos datos como páginas de redirección o imágenes para grupos de WhatsApp, una vez configurado el template deberías ver logs en la consola indicando que el servidor arrancó y escucha en http://127.0.0.1:8080 (o en el puerto que indique). Además, cuando llegan requests, verás entradas en tiempo real con IP/time/user-agent y, en caso de aceptar ubicación, lat/long.
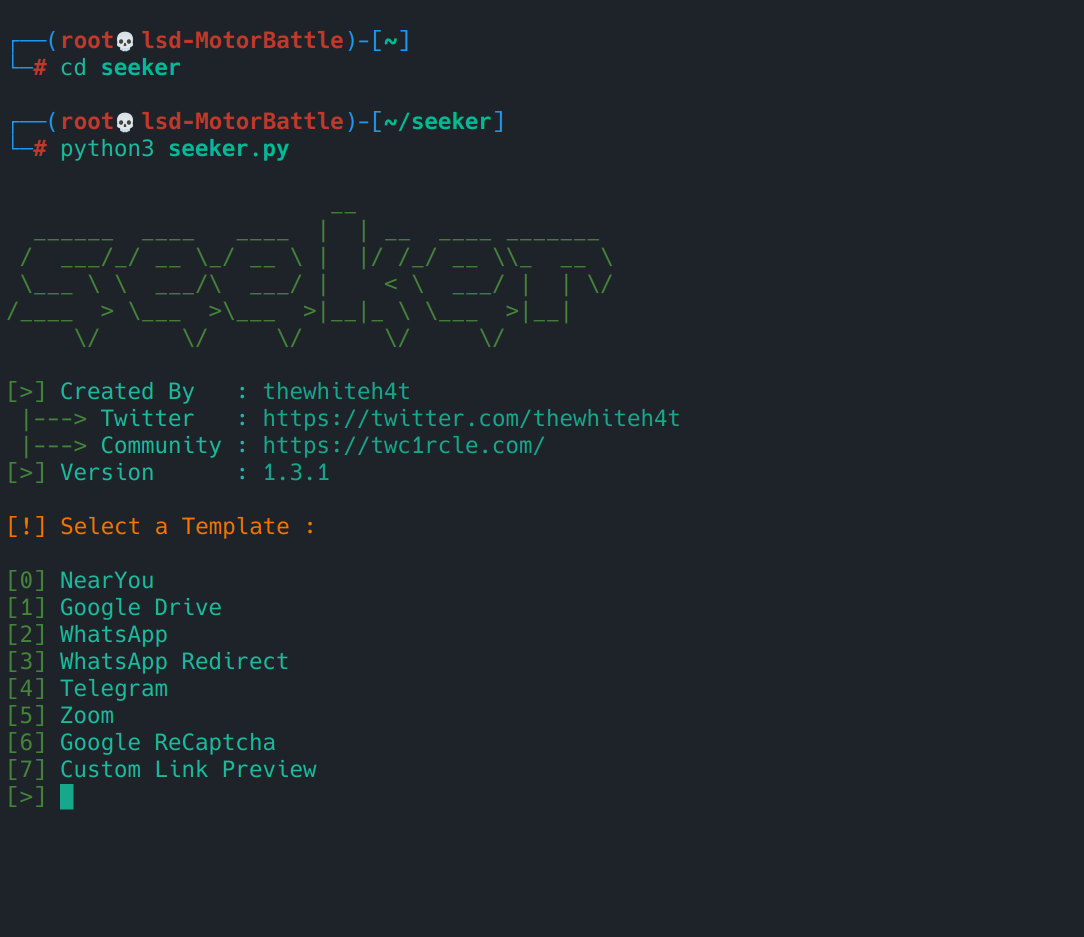
Con Seeker arrancando en localhost:8080 ya tenemos el servicio listo localmente. Ahora el siguiente paso es hacer que esa instancia sea accesible desde afuera, no para “pescar gente”, sino para ver cómo se presenta una instancia real desde un navegador externo, analizar las peticiones y los metadatos que deja, y extraer rasgos reutilizables para búsquedas en Censys/Shodan. Para ello montamos un reverse tunnel que nos dará una URL pública HTTPS que usaremos únicamente como anzuelo de prueba en un entorno controlado.
0x01.4 Reverse tunnels (localhost.run)
Los túneles reversos, crean un puente entre el puerto local de la VM y una URL pública en HTTPS; así exponemos el Seeker que ya está corriendo hacia afuera, solo para pruebas.
En este experimento probamos una de las opciones que tiene un repo de The Hackers Choice con trucos de este tipo, pero tu puedes experimentar con otras.
🔹 localhost.run con SSH
Es la forma más rápida porque no necesitas instalar nada adicional, solo usar SSH.
En tmux, ya con el panel que está corriendo Seeker, abres el del tunel con Ctrl-b % (si lo quieres vertical) y puedes usar Ctrl-b o para moverte entre paneles. Acá solo pones el comando:
ssh -R80:0:8080 -o StrictHostKeyChecking=accept-new nokey@localhost.run
¿Qué hace este comando?
-R80:0:8080: pide al servicio remoto abrir el puerto 80 y redirigirlo allocalhost:8080de nuestra VM.nokey@localhost.run: usuario “invitado” para crear el túnel.StrictHostKeyChecking=accept-new: evita el prompt de verificación de clave la primera vez.
Qué deberías ver: una URL pública tipo https://randomsub.lhr.life que apunta directo a tu puerto local.
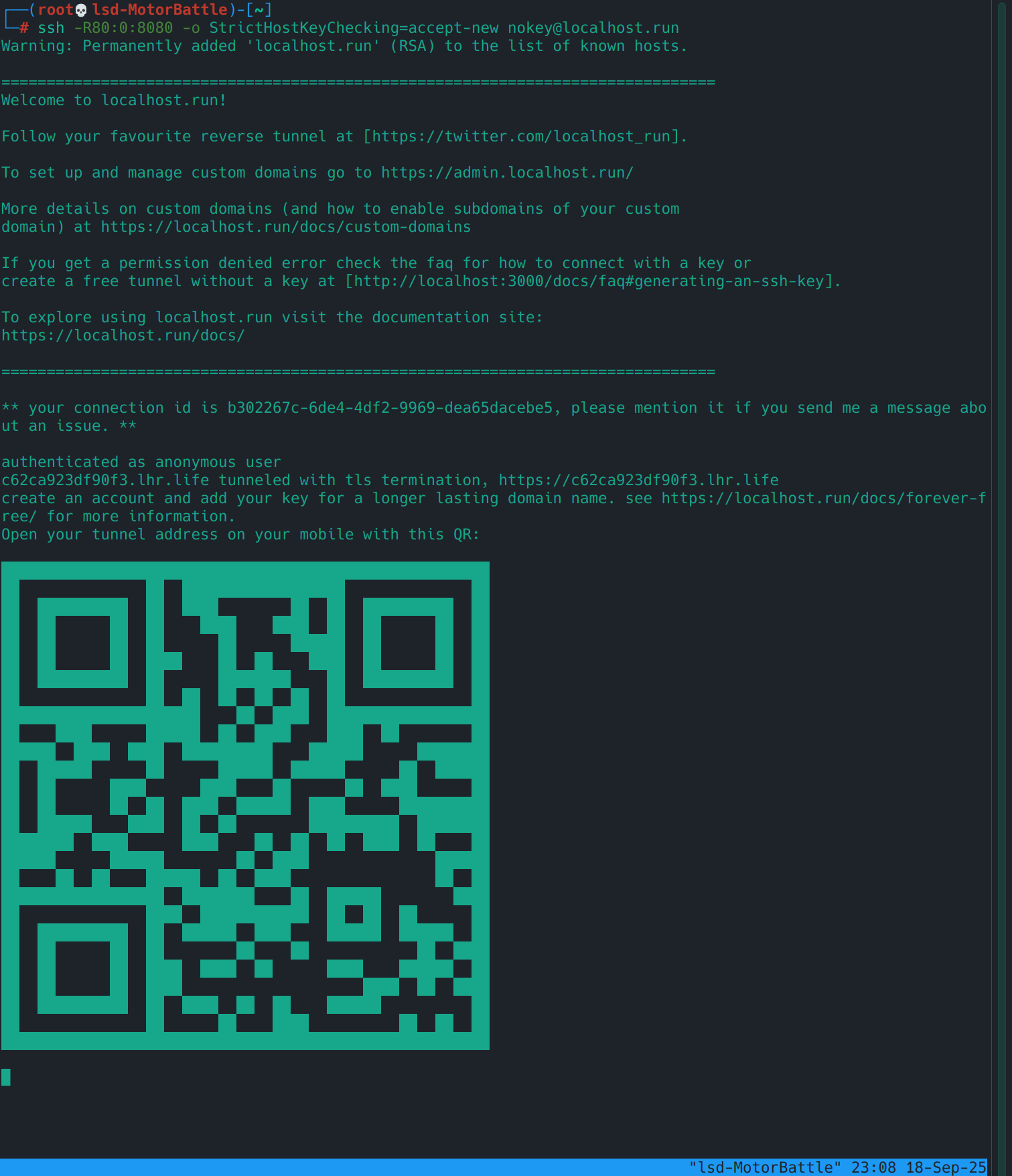
Este método tiene algunos pros y contras, por un lado es super fácil de montar y no instala nada en la VM, pero puede ser que el servicio sea inestable y limitado, y también puede ser que cambie la URL cada vez que la corres, pero nos funciona para el experimento, asi que vamos.
0x01.5 Seeker listo
Seeker quedó montado y accesible vía la URL pública del túnel; en la sesión de tmux dejamos el panel A con Seeker y el panel B con el túnel HTTPS. Con la URL ya podemos abrir la instancia desde un navegador limpio o un emulador y ver en vivo qué captura la plantilla (coords si aceptan, y/o metadata si niegan).
Pruebas
Con el navegador, si estás usando un perfil limpio, abre la URL pública, acá ya deberías ver la página de Seeker.
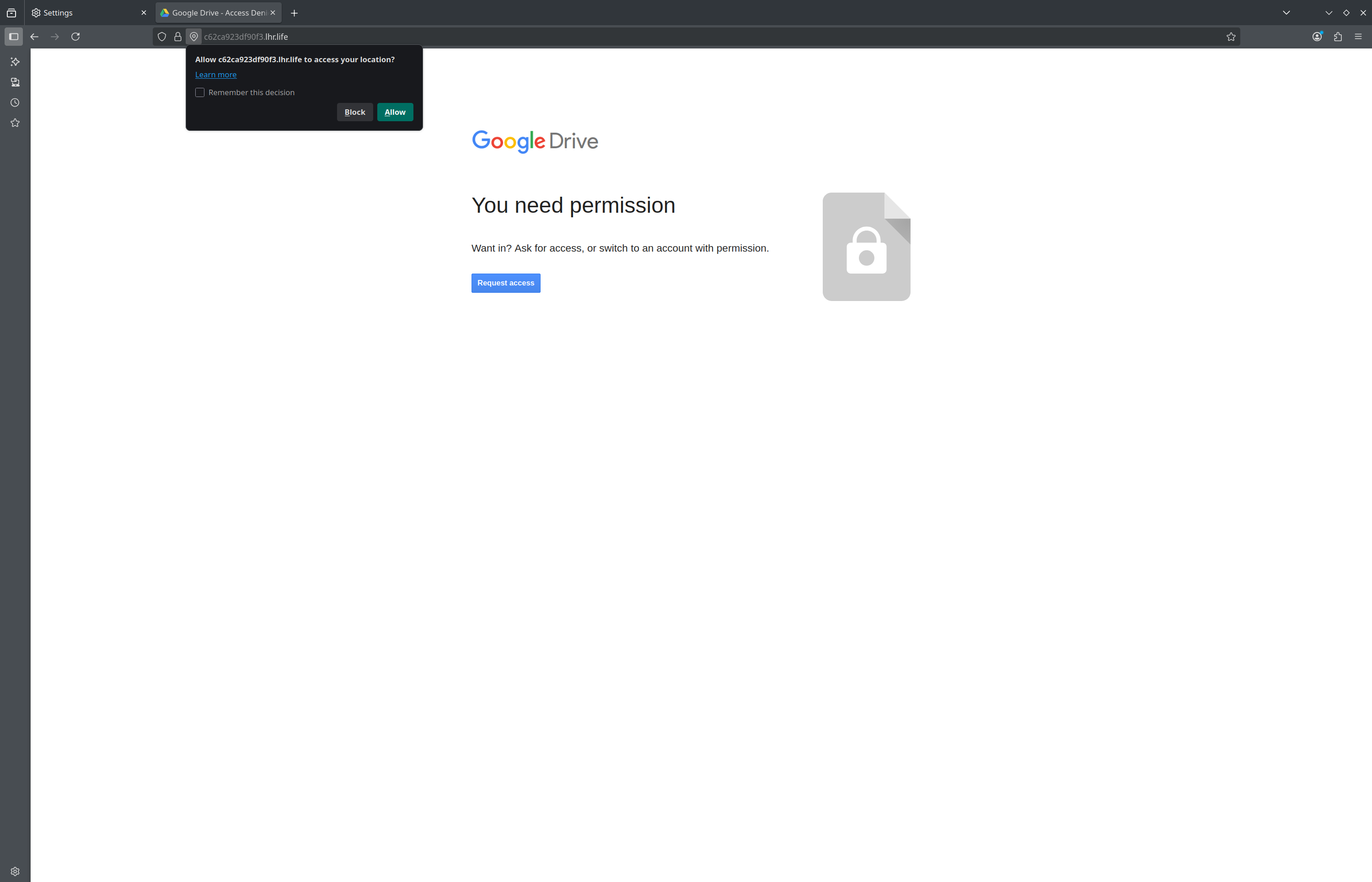
- Si aceptas ubicación → Seeker mostrará IP pública del cliente, user-agent, timestamp, coordenadas (lat, lon) y precisión en metros.
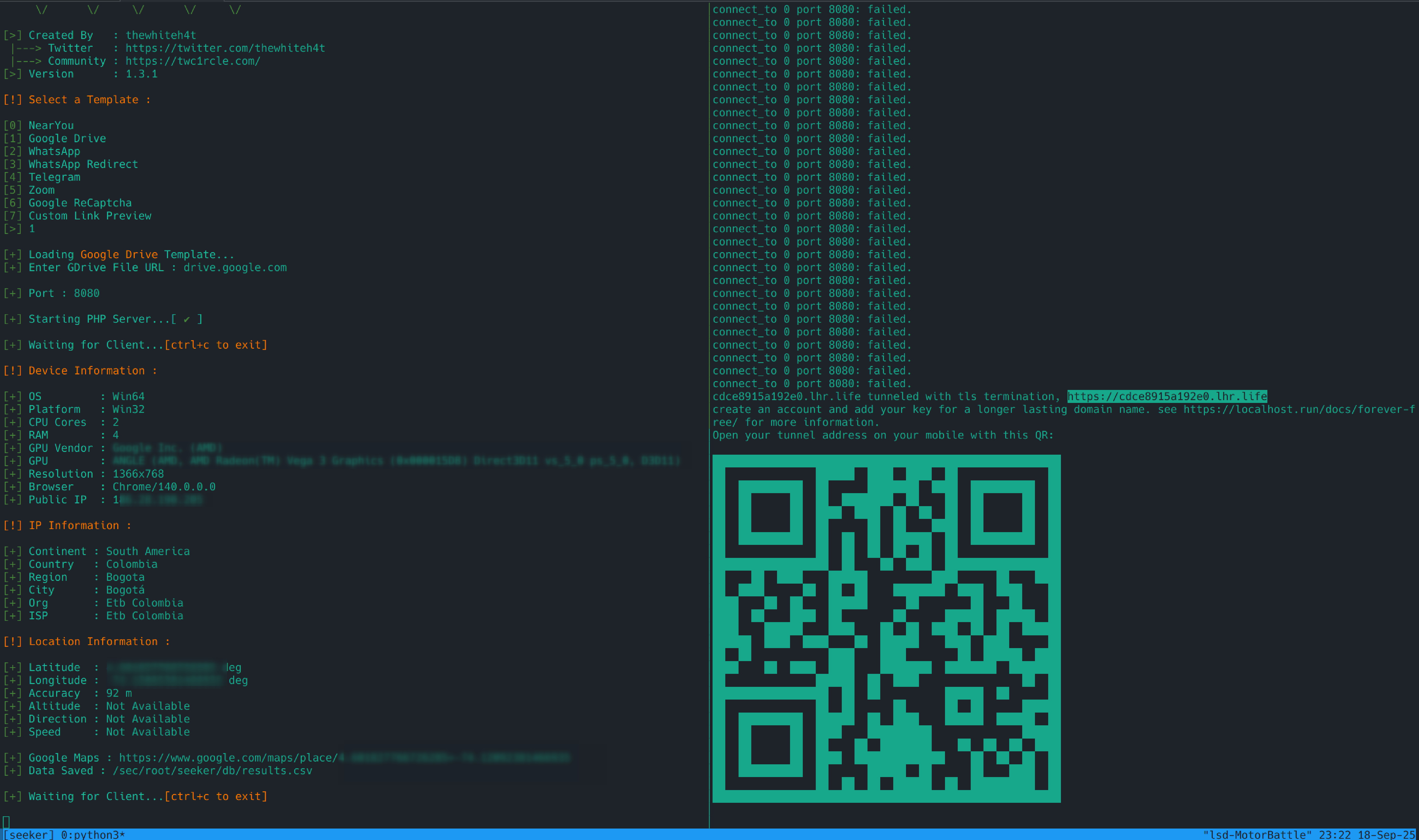
- Si niegas ubicación → verás que no aparecen coordenadas, pero sí IP, user-agent y otros metadatos (headers). Esto confirma que aún sin permiso hay información valiosa..
De Seeker al hunting
Ver que Seeker funciona es solo el primer paso. Lo que realmente nos interesa es sacar huellas que podamos reusar para cazar otras instancias: el favicon (/favicon.ico) actúa como un mini-fingerprint para correlación; el HTML title suele delatar plantillas enteras; los headers / banners HTTP (Server, Connection, redirecciones) ayudan a filtrar ruido y agrupar hosts hermanados; las rutas y plantillas (JS/CSS, paths estáticos) son huellas que se repiten y dejan rastros como migas de pan; y el combo certificados/TLS + IP/ASN nos da contexto de hosting y posibles clusters operativos. Con estos artefactos armamos consultas en Censys/Shodan y documentamos todo en Colander para generar IOCs listos para exportar —esto es investigación práctica, no curiosidad casual-.
Ahora sí, manos a la obra, primero nos vamos con OpSec y luego a lo divertido, el mapeo.
–[ 0x02 OpSec ]–
Antes de empezar a buscar, una pausa breve. En este experimento sí vamos a toparnos con infraestructura maliciosa y queremos estar listxs para interactuar con ella sin regalar datos o metadatos del lab. Nuestra receta mínima es: sacamos todo por Segfault (THC) usando un SOCKS5 via SSH y trabajamos con un navegador dedicado con perfil limpio. Si necesitamos “parecer” un teléfono, encadenamos un proxy HTTP con gost para que un emulador Android use la misma salida. Es simple, chévere y nos sirve de plantilla para futuros experimentos.
No es la única forma. Además, en nuestro caso usamos una VM prestada: no controlamos qué se registra o monitorea allí, así que para experimentos con infraestructura más peligrosa esta configuración podría quedarse corta, así que haz siempre una evaluación de riesgo —qué podría ver un tercero y si te importa que lo vea— y decide en consecuencia. Existen rutas alternativas (VPN, Tor, contenedores, VMs desechables, etc.); elegimos esta porque es rápida de montar y fácil de reutilizar.
0x02.1 Salida por segfault con SOCKS5 (SSH)
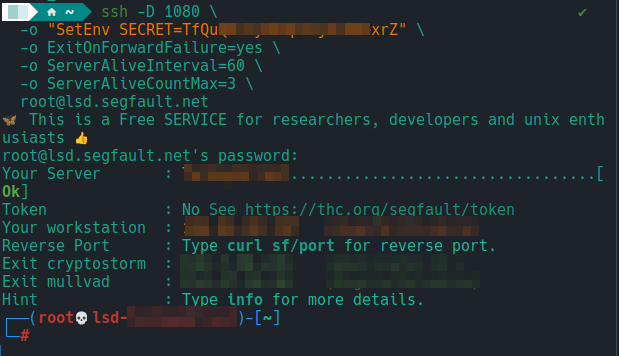
Qué hace: crea un proxy SOCKS5 local que tuneliza tu tráfico hacia segfault. Así, el destino ve la IP/ASN de segfault, no la de tu red del lab.
Comando (mínimo):
ssh -D 1080 -o "SetEnv SECRET=TuLlaveSecreta" root@lsd.segfault.net
Comando (robusto, con keepalive):
ssh -D 1080 \
-o "SetEnv SECRET=TuLlaveSecreta" \
-o ExitOnForwardFailure=yes \
-o ServerAliveInterval=60 \
-o ServerAliveCountMax=3 \
root@lsd.segfault.net
-D 1080: abre un SOCKS5 en127.0.0.1:1080.- Keepalive para que el túnel no se caiga en silencio.
0x02.2 Navegador dedicado (perfil limpio) → SOCKS5
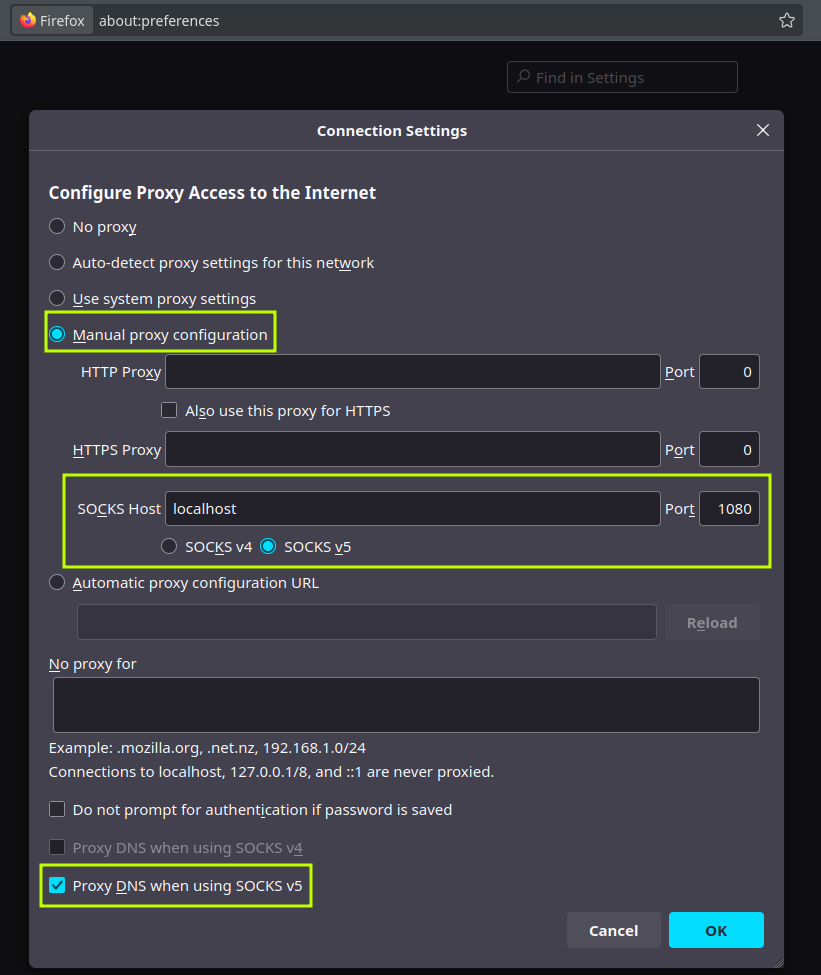
Idea: usar un navegador “limpio” (nuevo perfil, sin cookies/ extensiones personales) y apuntarlo al SOCKS5 del paso anterior. Importante: activar DNS por el proxy para evitar fugas.
-
Firefox: Preferencias → Red → Configurar → SOCKS5
127.0.0.1puerto1080. Enabout:configactiva:network.proxy.socks_remote_dns = true -
Chromium/Chrome: usa un perfil exclusivo y define el proxy en las opciones del sistema o vía línea de comando si lo necesitas, pero recuerda que no todos los caminos forzan DNS por SOCKS; si dudas, usa Firefox para esta parte.
Tip rápido de huella: idioma y zona horaria del navegador deberían ser coherentes con tu estrategia. Si no necesitas nada fancy, déjalo así.
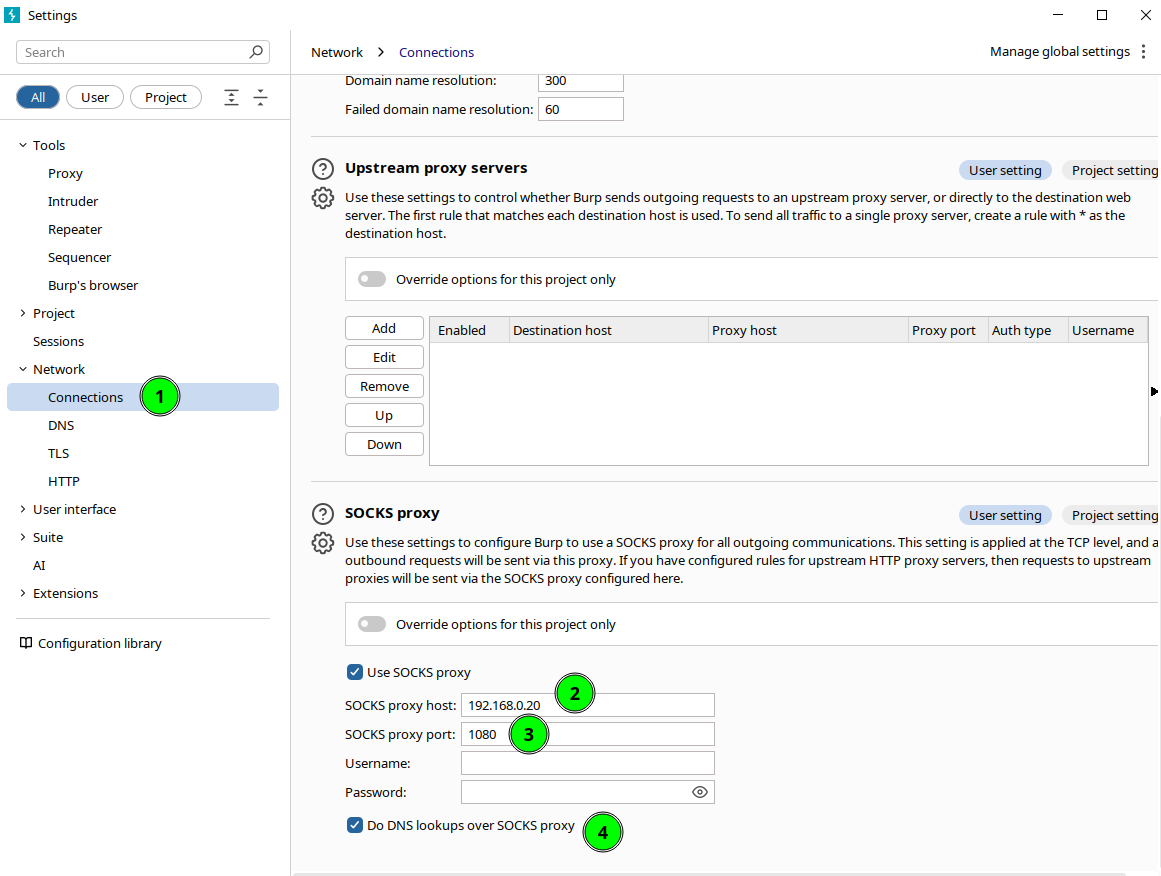
(Opcional) Interceptar con ZAP/Burp Si quieres mirar/editar tráfico:
- En ZAP/Burp configura SOCKS5 → 127.0.0.1:1080.
- Haz que el navegador apunte al HTTP proxy local de ZAP/Burp (p. ej.,
127.0.0.1:8080). ZAP/Burp → SOCKS5 → segfault.
0x02.3 Rama “móvil”: emulador Android con gost (HTTP→SOCKS)
¿Qué es gost? Una herramienta ligera (en Go) para convertir/encadenar proxies. La usamos para traducir HTTP ↔ SOCKS y así los emuladores (que hablan HTTP proxy, no SOCKS) puedan aprovechar nuestro túnel.
Puente local HTTP→SOCKS (en tu compu):
gost -L=http://127.0.0.1:8081 -F=socks5://127.0.0.1:1080
-L=http://127.0.0.1:8081abre un proxy HTTP local en:8081.-F=socks5://127.0.0.1:1080lo encadena al SOCKS5 del SSH.
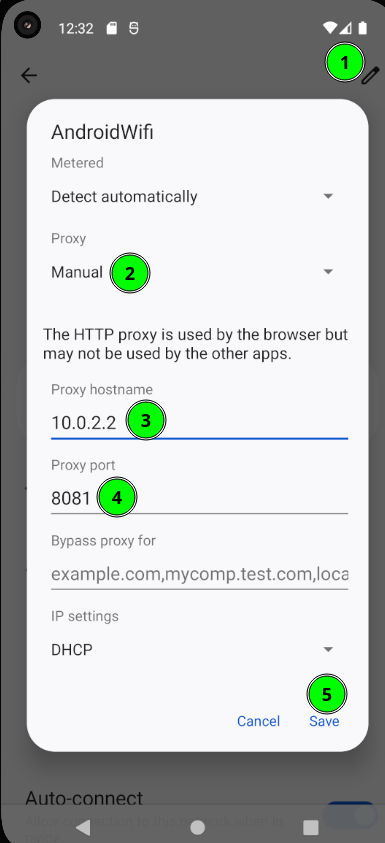
Emulador Android (AVD) Configura Wi-Fi → Proxy manual:
- Host:
10.0.2.2(el emulador ve al host así; en Genymotion suele ser10.0.3.2) - Puerto:
8081
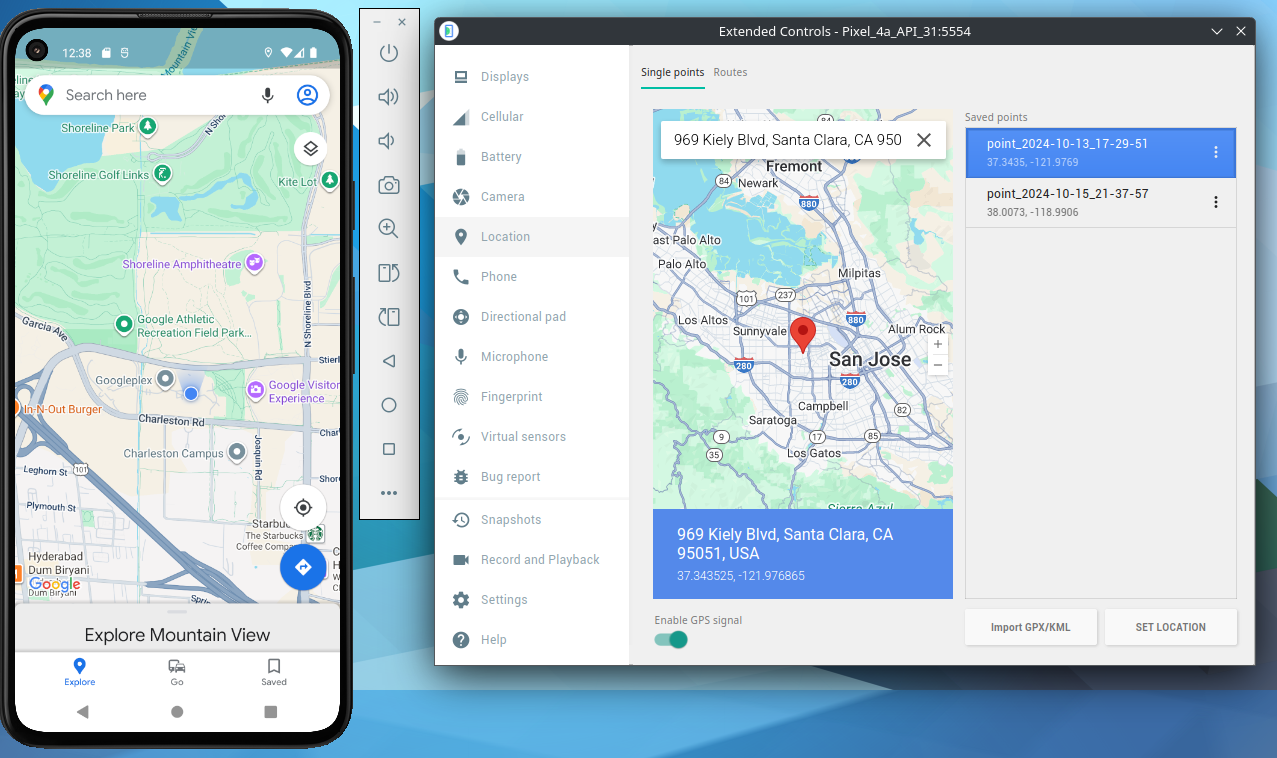
Ubicación simulada (opcional, muy útil con Seeker) Usa las herramientas del emulador para fijar coordenadas y probar cómo Seeker registra ubicación sin exponer la real.
0x02.4 Diagrama (dos ramas, clarito)
[Compu del laboratorio]
│
SSH -D 1080 (SOCKS5 local)
│
┌──────────────┴───────────────┐
│ │
│ RUTA ESCRITORIO │ RUTA MÓVIL
│ (Navegador limpio) │ (Emulador Android)
│ │
Navegador → (opcional ZAP/Burp) Emulador
│ │
│ gost HTTP :8081 → SOCKS5 :1080
└──────────────┬───────────────┘
│
segfault
│
Infraestructura Seeker
Notas de cierre
- Con esta cadena, todo sale por segfault; tu red del lab no asoma la cabeza.
- El navegador dedicado evita mezclar cookies/ extensiones/ idioma/zona de tu día a día.
- La rama móvil con
gostte deja probar “como teléfono” sin exponer el host y con ubicación simulada. Es nuestra recomendación para este experimento. - Si tu caso pide otra cosa (VMs, Tor, VPN), cámbiala sin pena. Esta es nuestra recomendación base porque es corta, práctica y reusable para lo que viene.
–[ 0x03 A la caza (favicons primero) ]–
Primero, las herramientas. Censys y Shodan no “leen” páginas como un buscador normal: indexan metadatos de servicios (banners, headers, certificados, títulos HTML, favicons…). Por eso nos sirven tanto aquí: Seeker recicla plantillas con favicons y títulos muy reconocibles; si pescas uno, es común que salgan varios más. Para consultas finas, Censys expone un lenguaje de búsqueda a nivel de campos (CenQL) y, sí, puedes filtrar por favicons.hashes o html_title; Shodan tiene su propia sintaxis.
Niveles de acceso
- Sin cuenta: curioseas poco.
- Cuenta gratuita: más resultados, pero con créditos y límites visibles (abrir páginas extra, usar API, etc.).
- De pago: cuotas mucho más amplias y, sobre todo, históricos: ver “cuándo” se observó algo, comparar estados en el tiempo, etc. (útil para correlacionar campañas). Aquí no usaremos históricos pagos, pero existen y son oro en investigaciones largas. Para Shodan, el acceso también va por créditos de consulta (filtros, paginar… gastan).
Mini-tip: en Shodan, el filtro por favicon no usa SHA-256; usa MurmurHash3 (mmh3) sobre el favicon. No mezcles los hashes.
0x03.1 Punto de partida: favicon del template reCAPTCHA (con Censys)
Vamos a empezar por lo pequeño que deja una pista grande: el favicon del template de Google reCAPTCHA en Seeker. La idea es sacar el SHA-256 del favicon del template y buscarlo en Censys (sin cuenta).
¿Qué es un favicon? El favicon es el iconito que ves en la pestaña del navegador y en los marcadores. Técnicamente es un archivo pequeño (ICO/PNG/SVG) que el sitio sirve (típicamente
/favicon.icoo referenciado en el<head>). Como muchas plantillas reutilizan el mismo favicon, su hash se vuelve un “mini-fingerprint” fácil de buscar y correlacionar entre instancias (ideal para cazar infra reciclada como la de Seeker).
$ cd seeker/template/captcha
$ ls
anchor.html css favicon.ico fonts images index_temp.html js
$ sha256sum favicon.ico
4673c3ef82f32e37d0021d3683b5c132dbab0942e7137427fc9716235289c678 favicon.ico
$
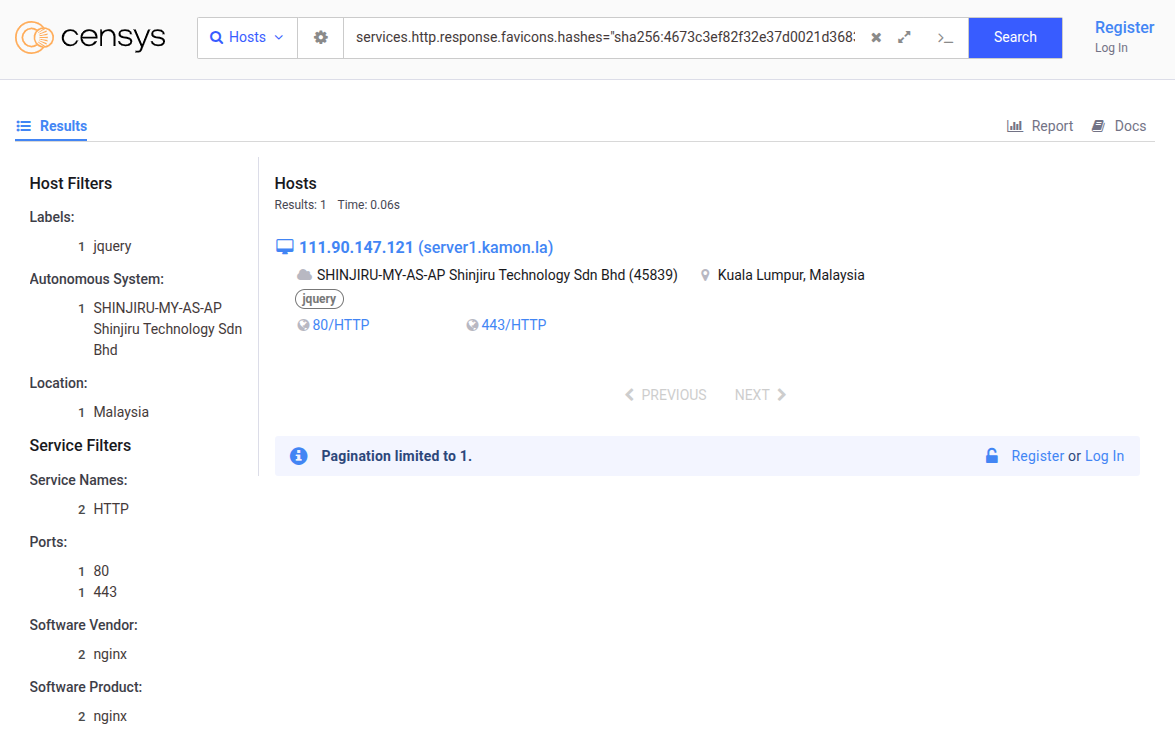
Con el hash listo, en Censys (https://search.censys.io/) buscamos así (usa el prefijo sha256: tal cual):
services.http.response.favicons.hashes="sha256:4673c3ef82f32e37d0021d3683b5c132dbab0942e7137427fc9716235289c678""
Ese campo existe y acepta “sha256:<hex>” como valor; si dudas, abre cualquier host y mira cómo Censys lo nombra en su panel.
0x03.1.1 Lo que vimos en el primer tiro
En la instancia que encontramos (que usaremos como ejemplo) Censys mostraba que el servicio de Seeker se observó por última vez el 4 de septiembre de 2025, mientras que otros servicios del mismo host siguen activos al momento de escribir esto (10 días después). Ese contraste temporal es justo el tipo de pista que ayuda a entender si apagaron, cambiaron o ajustaron algo.
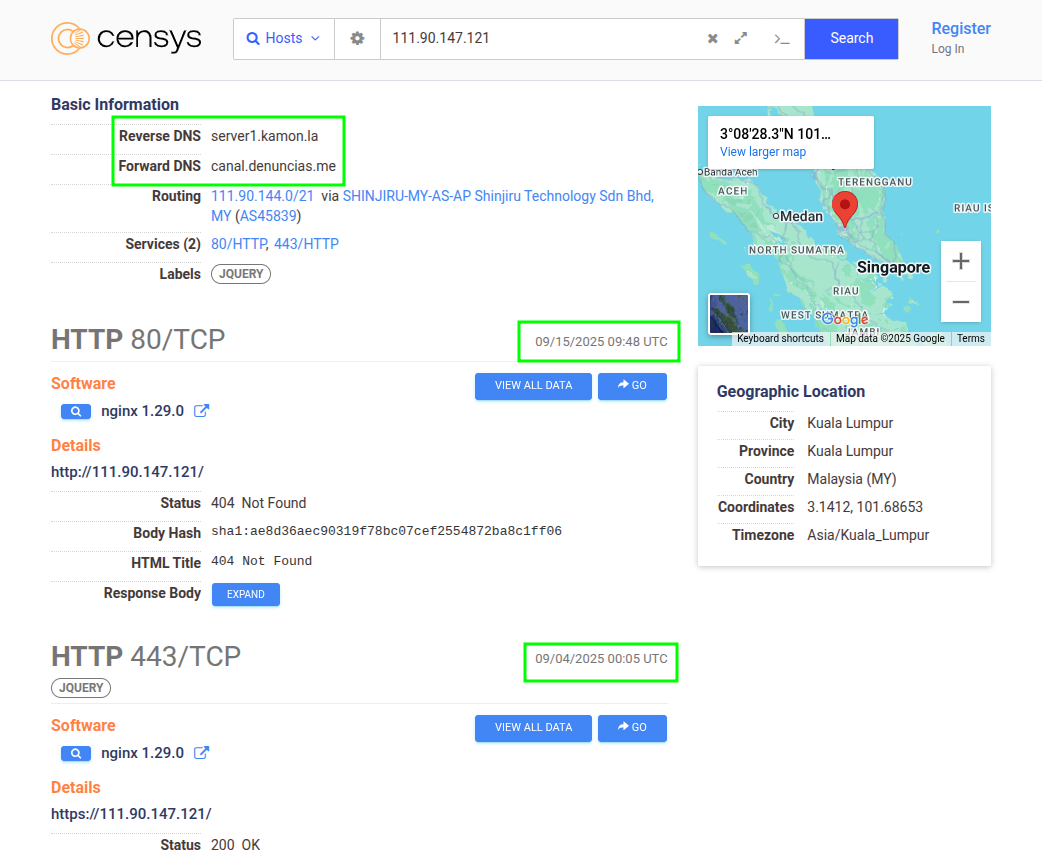
En esa misma ficha aparecían dos dominios asociados. Uno de ellos —canal.denuncias.me— nos interesa especialmente por el contexto hispano. Tomamos nota (IP, dominios, ASN, puertos, cualquier redirección que veas en la respuesta HTTP). La organización de esos datos la dejamos para el próximo capítulo.
0x03.1.2 Pivot sin perder el hilo: del favicon al título (reCAPTCHA)
Cuando el favicon no está (o desaparece), el hash deja de servir. Ahí toca cambiar de pista: el título HTML.
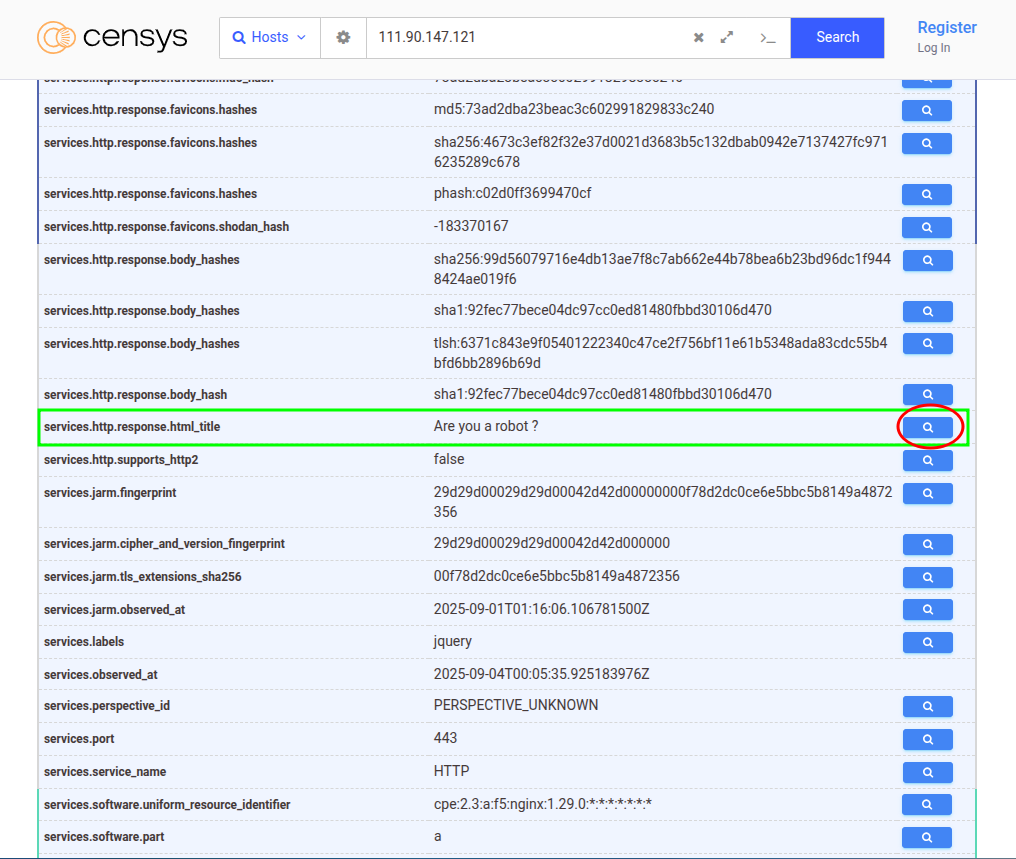
- En la ficha del servicio de Seeker, haz clic en “View all data”.
- En la tabla, ubica el campo
html_title(debería verse así):services.http.response.html_title = "Are you a robot ?" - A la izquierda de ese valor hay una lupita. Haz clic y Censys te armará una búsqueda por ese mismo título en todo su dataset.
- Ejecuta. Aparecerá otra instancia de Seeker reCAPTCHA. Esta no salió con el favicon porque no tiene (o se lo borraron), pero el título la delata.
Si prefieres correrlo a mano:
services.http.response.html_title="Are you a robot \?"
(El campo html_title es buscable; Censys lo documenta y puedes usar comillas para coincidencia exacta).
Nota metodológica: En nuestra corrida inicial encontramos el host “B” por favicon. Al revalidar para este write-up ya no aparecía: el favicon había desaparecido. Con históricos pagos podríamos cotejar el cambio en el tiempo. Lo dejamos como una hipótesis razonable, no como certeza.
0x03.1.3 Afinar (cuando el favicon “se repite demasiado”)
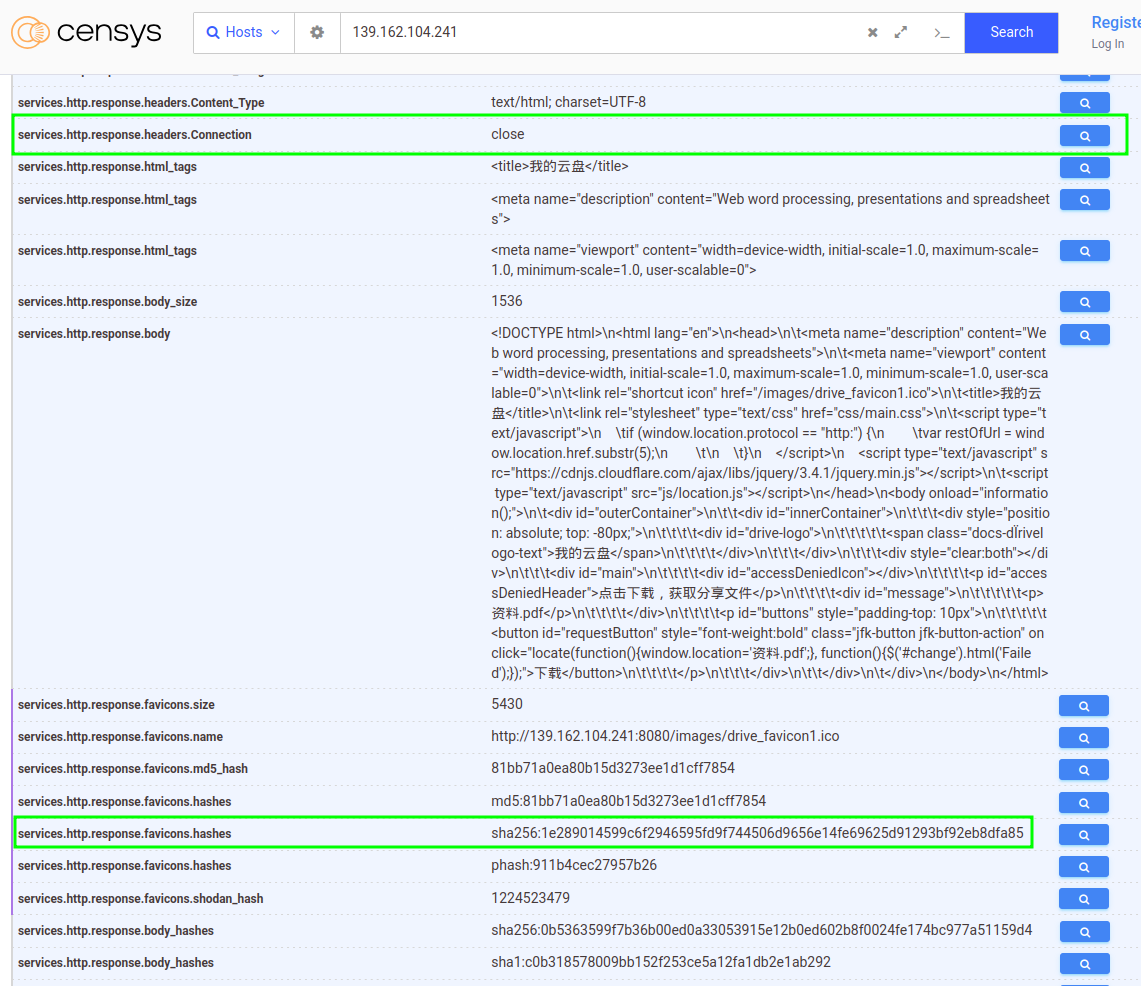
Si tu hash devuelve demasiados sitios (incluidos legítimos), añade rasgos que hayas observado en instancias reales: headers, título, paths típicos. Por ejemplo, cuando buscamos instancias del template de Google Drive encontramos no solo instancias de Seeker sino otras que hacen ruido en los resultados. En nuestro caso, hemos observado que en las instancias de Seeker el header “Connection” de la respuesta siempre esta en “close”. La mayoría de los hosts que no son Seeker, normalmente tienen este header en “keep-alive”. Combinar favicon + header conocido puede acotar la búsqueda a solo Seeker:
services.http.response.favicons.hashes="sha256:1e289014599c6f2946595fd9f744506d9656e14fe69625d91293bf92eb8dfa85" and services.http.response.headers: (key: `Connection` and value.headers: `close`)
(Los nombres exactos de los campos pueden variar por dataset; cópialos tal cual aparecen en la ficha del host).
0x03.1.4 ¿Qué guardar mientras cazas y por qué?
Cada match te da piezas: IP, dominios, ASN, puertos, título, redirecciones, geografía. Con eso puedes contextualizar: ¿dónde está el servidor?, ¿qué cadena/título sugiere la plantilla?, ¿apunta a alguna puerta de entrada concreta? Así se levantan hipótesis de campañas o se reconocen IOCs que valen para más países (en nuestro ejemplo, el dominio en español es un IOC de interés regional).
0x03.2 A la caza (segunda parte: Shodan, “Near You” sin favicon)
Seguimos con la misma lógica pero ahora del lado de Shodan que esta vez usaremos con un usuario registrado pero sin pagar. No vamos a re-explicar la herramienta: directo al grano con el template “Near You” de Seeker. Este bicho es minimalista (arranca sin pedir imágenes ni datos extra), finge ser un servicio “basado en tu ubicación” —lo justo para tentar a la víctima a autorizar geolocalización— y, clave para nosotros porque no trae favicon. Así que entramos por título.
Sacar el título del template (una vez, desde código)
Primero confirmamos el <title> del template “Near You”.
$ cd seeker/template/nearyou
$ ls
css index_temp.html js
$ grep "<title>" index_temp.html
<title>Near You | Meet New People, Make New Friends</title>
$
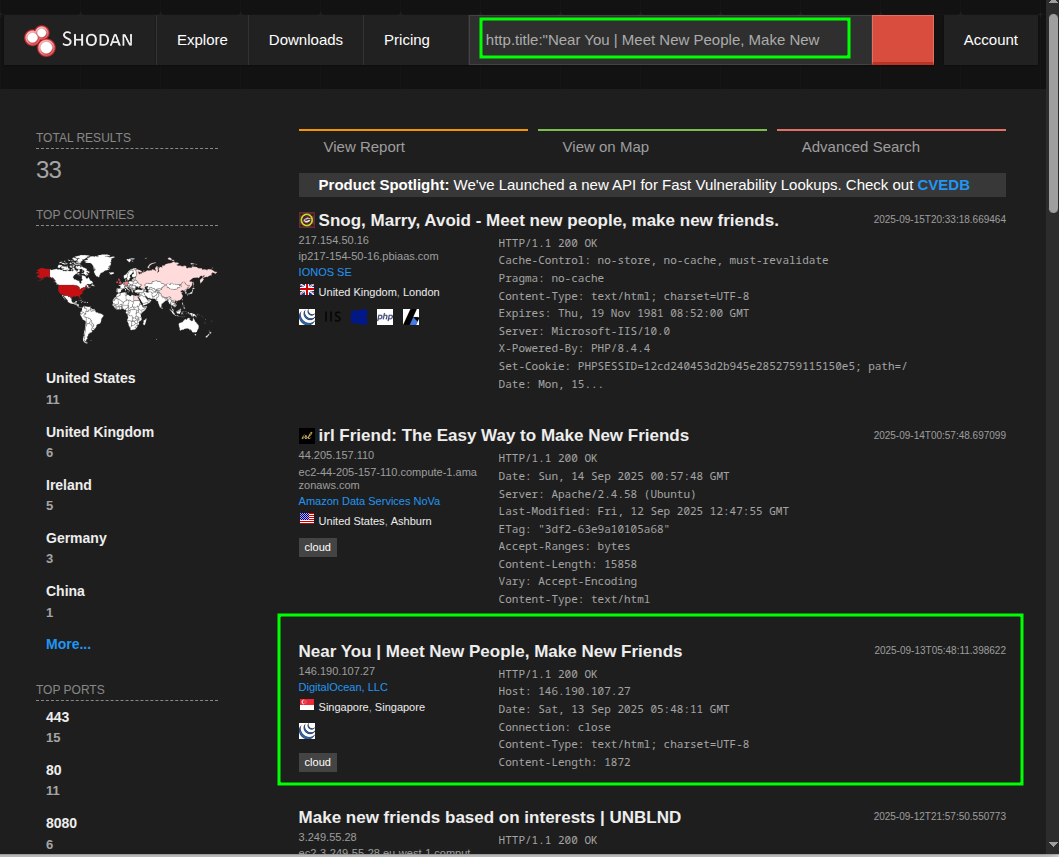
Con el título validado, lo buscamos en Shodan tal cual:
http.title:"Near You | Meet New People, Make New Friends"
Va a salir ruido, es normal, hay servicios inocentes que coinciden por texto. Lo que nos interesa es el host donde el título calza literal y, al abrir la ficha, encontramos el puerto/servicio donde corre Seeker.
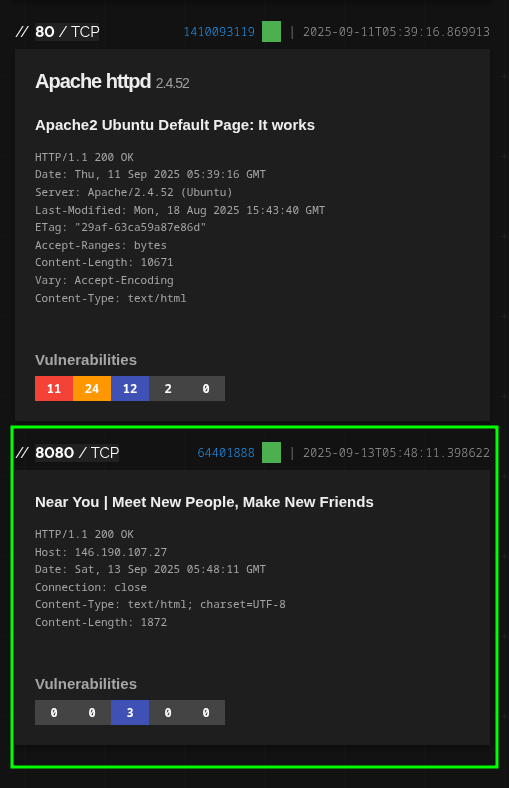
0x03.2.1 Pivot limpio dentro de Shodan
Arriba del bloque del servicio verás un badge verde. Haz clic ahí y se despliegan varios hashes calculados por Shodan para ese banner. El que nos interesa es http.title_hash. Haz clic en ese hash, ahora Shodan te arma automáticamente una búsqueda filtrada por ese fingerprint de título. Resultado: te quedas solo con páginas que comparten ese título —ahí aparece otra instancia de Seeker “Near You”— y, de ñapa, otra muy sospechosa que parece phishing de otra familia.
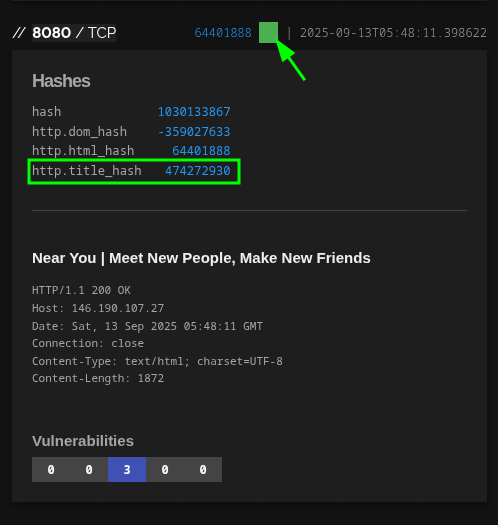
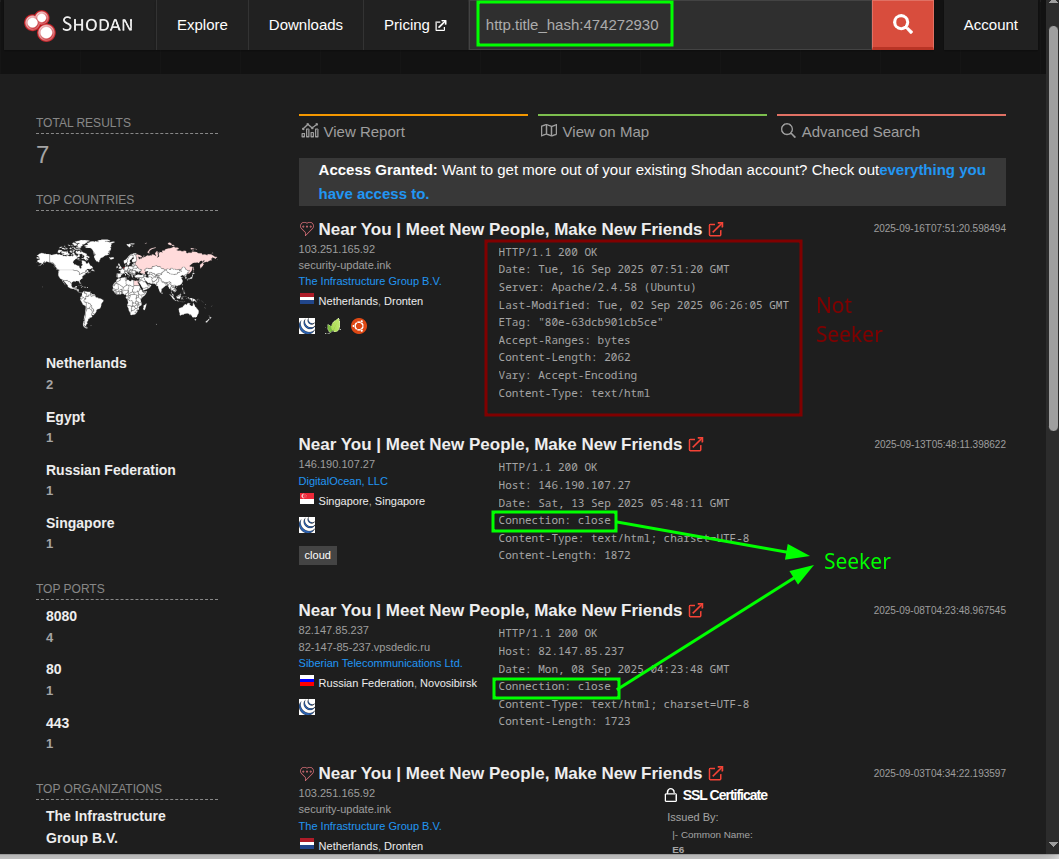
Con eso aprendemos dos cosas: (1) cuando no hay favicon, el título sigue siendo un anzuelo sólido; (2) pivoteando desde el detalle de un servicio a su fingerprint (hash del título), bajamos el ruido a casi cero sin salir de la propia interfaz.
0x03.2.2 ¿Qué nos guardamos?
Nada sofisticado: host, puerto, ASN, dominio si lo hay, y cualquier redirección o ruta interesante que veas en la respuesta. La organización fina va en la siguiente sección; por ahora, solo asegúrate de que cada hallazgo tenga su mínima ficha.
0x03.3 Un paso más sobre el contexto (sin volarnos la cabeza)
Aquí es donde deja de ser “buscar cadenas” y empieza la inteligencia de verdad. Con muy poco ya se puede:
- Atar contenido a campañas: si la página de phishing redirige siempre a cierto formulario, dominio o landing específico, ya tienes un vínculo operativo. Eso alcanza para levantar una alerta a un colectivo o región concreta.
- Mirar el mapa: filtrar por país/ASN/organización revela si la cosa se concentra en proveedores o zonas concretas. Si el mismo título aparece en ASNs repetidos, es una pista de infra compartida.
- Certificados/TLS (para otro write-up): cadenas, emisores y huellas de cert suelen ser oro para unir infra dispersa. Aquí no lo tocamos para no abrir otro melón.
- Tiempo: los históricos (normalmente de pago) te dejan ver cuándo apareció o desapareció un rasgo. Eso ayuda a coser campañas y, si hay publicaciones previas, hasta atribución plausible. No lo usaremos aquí, pero es la herramienta que querrás cuando esto escale.
Cerramos con la misma invitación de siempre: esto apenas araña la superficie de lo que permiten Censys y Shodan. No venimos a inventar nada: venimos a mostrar cómo lo estamos haciendo mientras aprendemos. Lo que esperamos es que pique la curiosidad y se sumen ojos. Lxs adversarixs juegan en serio; nos toca responder igual.
–[ 0x04 Documentar hallazgos en Colander ]–
Colander, para nosotrxs, es el “cuaderno de campo” donde un caso deja de ser un montón de pestañas y notas sueltas y se vuelve conocimiento navegable. Es parte de la PiRogue Tool Suite (PTS) —sí, la misma gente de PiRogue— y está pensado para investigaciones digitales y gestión de casos: organizas eventos, artefactos, observables, los conectas en un caso, y de ahí puedes generar reportes, feeds e incluso reglas. No haremos un tutorial aquí; si quieres aprender a usarlo bien, toca pasar por la doc oficial de PTS/Colander (vale la pena).
Este capítulo va de metodología aplicada: cómo tomamos lo que encontramos “en la caza” y lo bajamos a Colander.
Antes de teclear: observables vs. IOCs (y la duda sana)
En este experimento con Seeker aparecen muchísimas IPs, URLs y puertos (el 8080 es el default de Seeker), pero cuando Seeker se usa “en producción” suele haber un túnel/puente HTTPS delante. Entonces… ¿http://IP:8080/ es un IOC o sólo un observable? Respuesta corta: depende del uso.
- Un observable es algo que viste tal cual (una IP, una URL, un title), útil para buscar/correlacionar.
- Un IOC sugiere malicia accionable (sirve para bloquear/alertar con bajo costo de falsos positivos).
Si alguien aplicara a ciegas un bloqueo con base en tus IPs/URLs “de laboratorio”, podría afectar hosts legítimos (p. ej., un servidor que temporalmente alojó una instancia de prueba o un endpoint de un CDN). La línea entre “observable” e “IOC” se traza con contexto (más abajo volvemos a eso). Nuestra regla práctica: subimos primero observables, los etiquetamos y, cuando hay evidencia suficiente, ascendemos algunos a IOC.
Cómo lo estamos modelando (nuestro flujo, no “el correcto”)
Para este trabajo decidimos crear en Colander una amenaza (Threat) por cada template de Seeker (reCAPTCHA, “Near You”, Telegram, etc.) y asociar los observables a esas amenazas. A veces un host servía más de una instancia con templates distintos; en esos casos hay relaciones cruzadas y preferimos no forzar una historia:
- Si el vínculo era claro, colgábamos el observable del template correspondiente.
- Si no lo era, lo asociábamos a una instancia “genérica” de Seeker y dejábamos nota de la ambigüedad.
¿La verdad? Gimnasia mental. No hay un único esquema perfecto. Aprendimos que la única forma de resolver estos dilemas es haciéndolo: ensuciarse las manos, probar, cambiar etiquetas, volver a mirar. Este capítulo muestra un ejemplo concreto (el del dominio en español que nos interesó) para que se vea el “cómo” y el “por qué” detrás de cada asociación.
El ejemplo que vamos a bajar a Colander
Previamente hemos creado un caso en Colander y una amenaza de tipo phishing para “Seeker captcha”
En la caza inicial que hicimos con Censys encontramos un host muy interesante que entre otras cosas tenia un dominio en español que nos llamó la atención: canal.denuncias.me. veamos como luce este host en Censys:
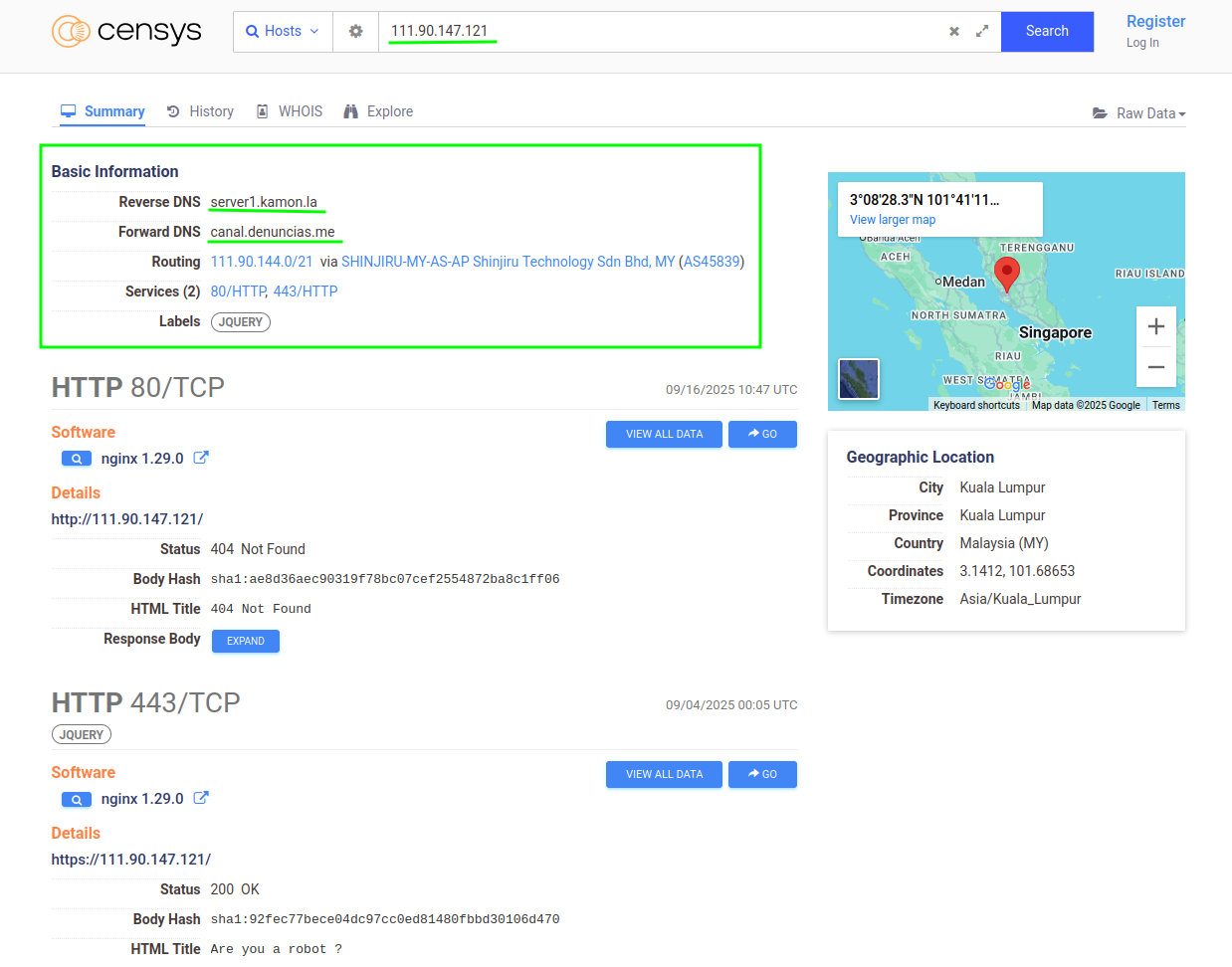
Lo primero que podemos hacer es usar la funcion de “investigate” de Colander y ver que resultado nos arroja buscando la IP:
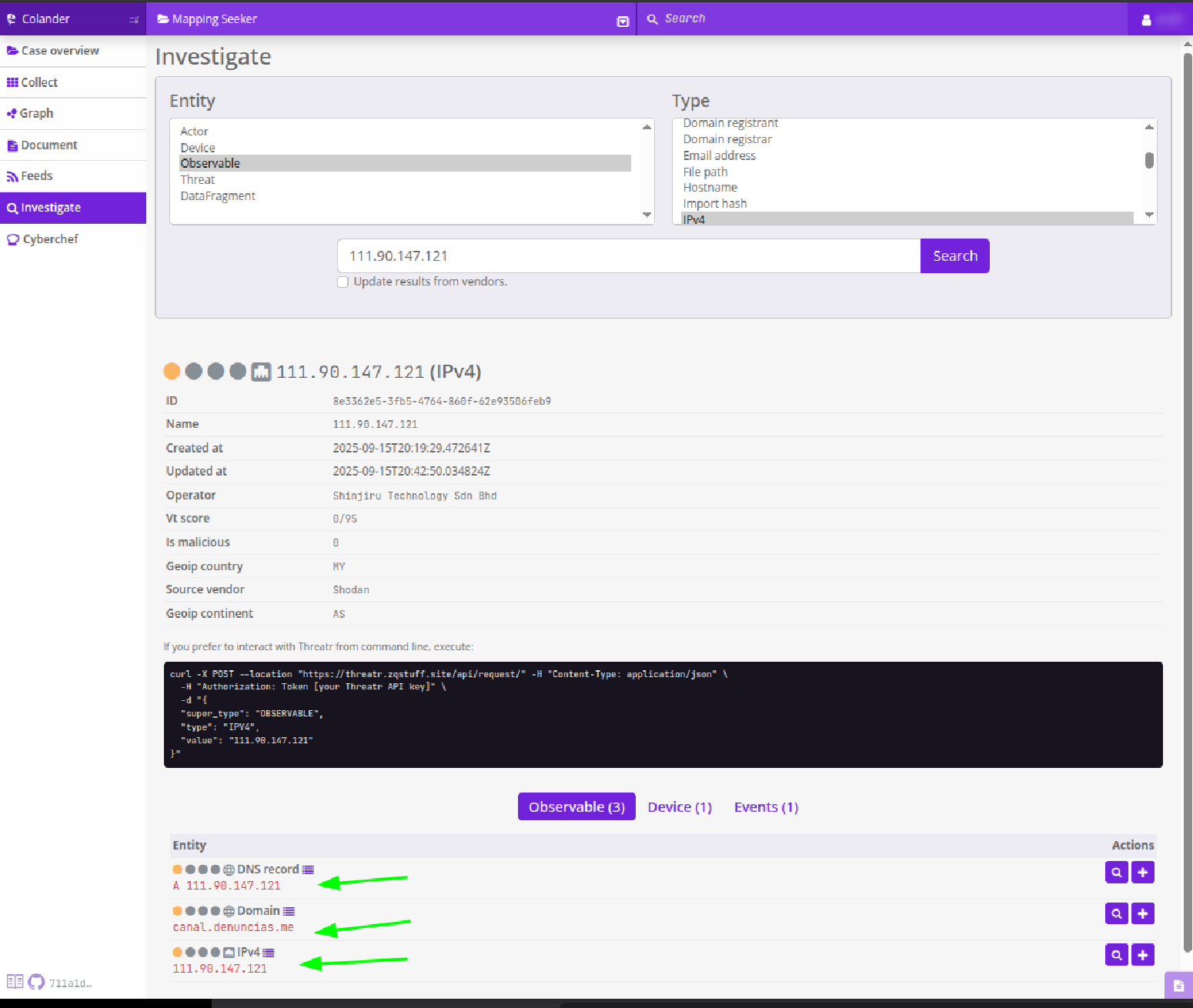
En la parte de abajo podemos ver que obtenemos 3 observables (entre otras cosas), entre ellos el dominio que mas nos interesa. si hacemos click en el + frente a los observables podemos añadirlos al caso y con la ventaja que subirán también los datos extraidos por Threatr (un servicio que trae colander que se conecta con otras plataformas de inteligencia de amenazas para obtener mas información de los observables que investiguemos, incluye Shodan!).
Además, como en Censys, tenemos la lupita para privotar, en este caso podemos investigar el dominio y luego añadirlo al caso.
Pero tenemos otro dato importante aca, un “reverse dns” que no aparece en los observables que nos mostró la investigación de la IP en Colander, podemos usar la misma herramienta de investigación y ver que encuentra Colander para ese dominio, veamos:
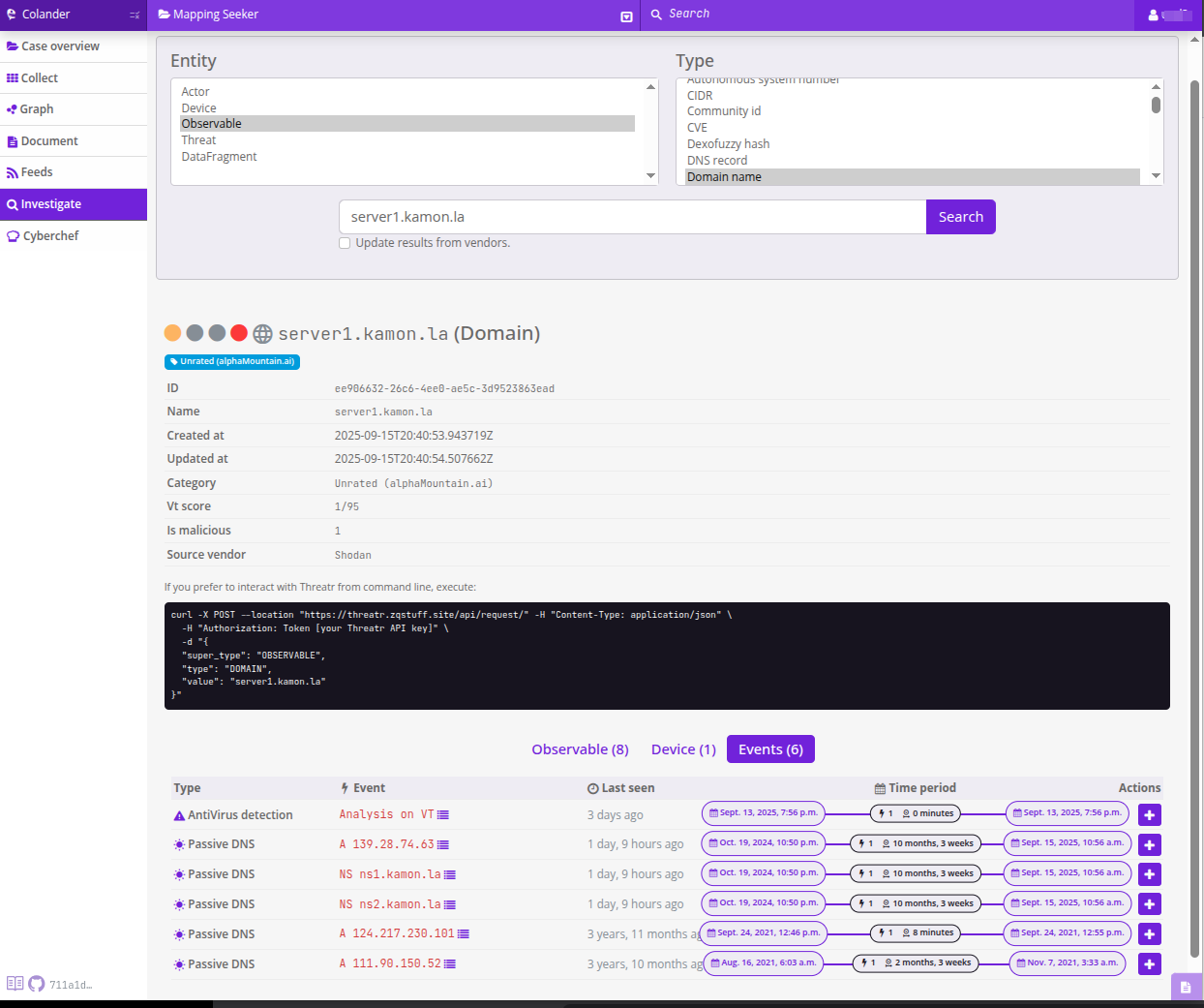
Aunque tambien tenemos varios observables, en este caso estamos viendo los “eventos”, el primero nos muestra que en un análisis de virus total, hace 3 dias, esta url fue detectada como maliciosa, osea alguien mas se topó con esto hace poco, interesante.
En este caso añadimos el dominio y el evento al caso usando los iconos de +.
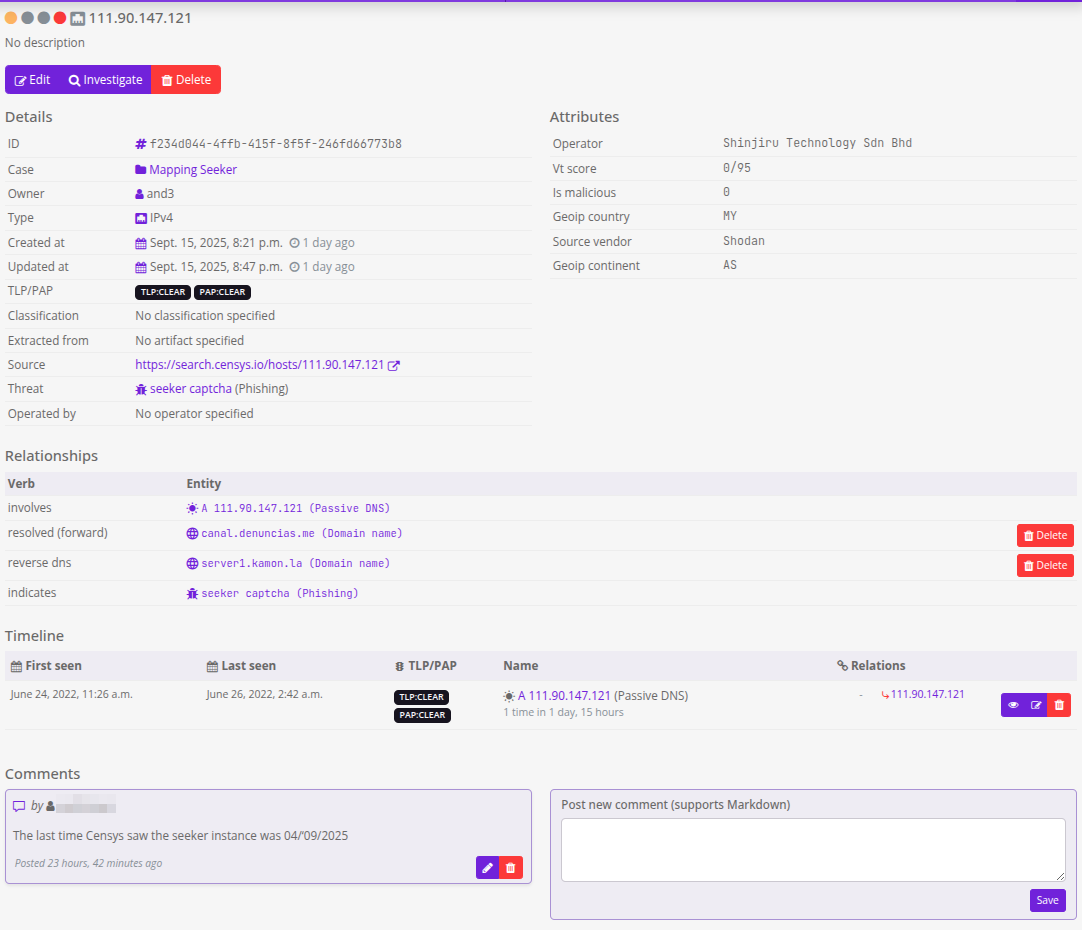
Que añadimos y que no, es una gran pregunta, nosotrxs nos limitamos a los dominios, la IP, y un par de eventos y todos los asociamos con la amenaza “Seeker captcha”. Un ejemplo de como se ve la entrada para la IP es este:
La funcionalidad de Graph en colander nos da una idea mejor de como lucen las relaciones, el siguente patanllazo corresponde a un sub-graph de esta amenaza especiífica:
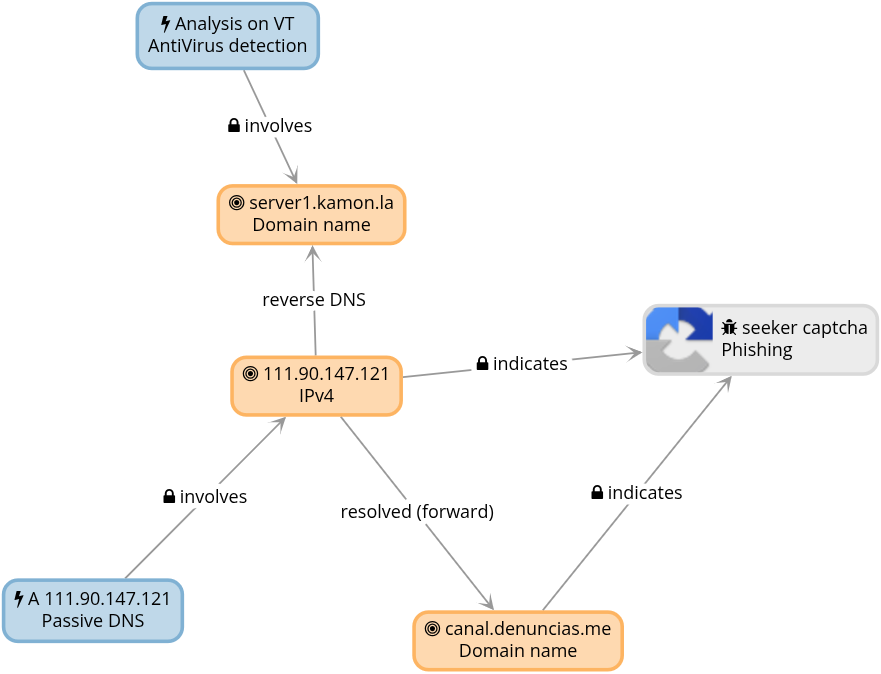
el Graph completo de este experimento (hasta donde va), luce así:
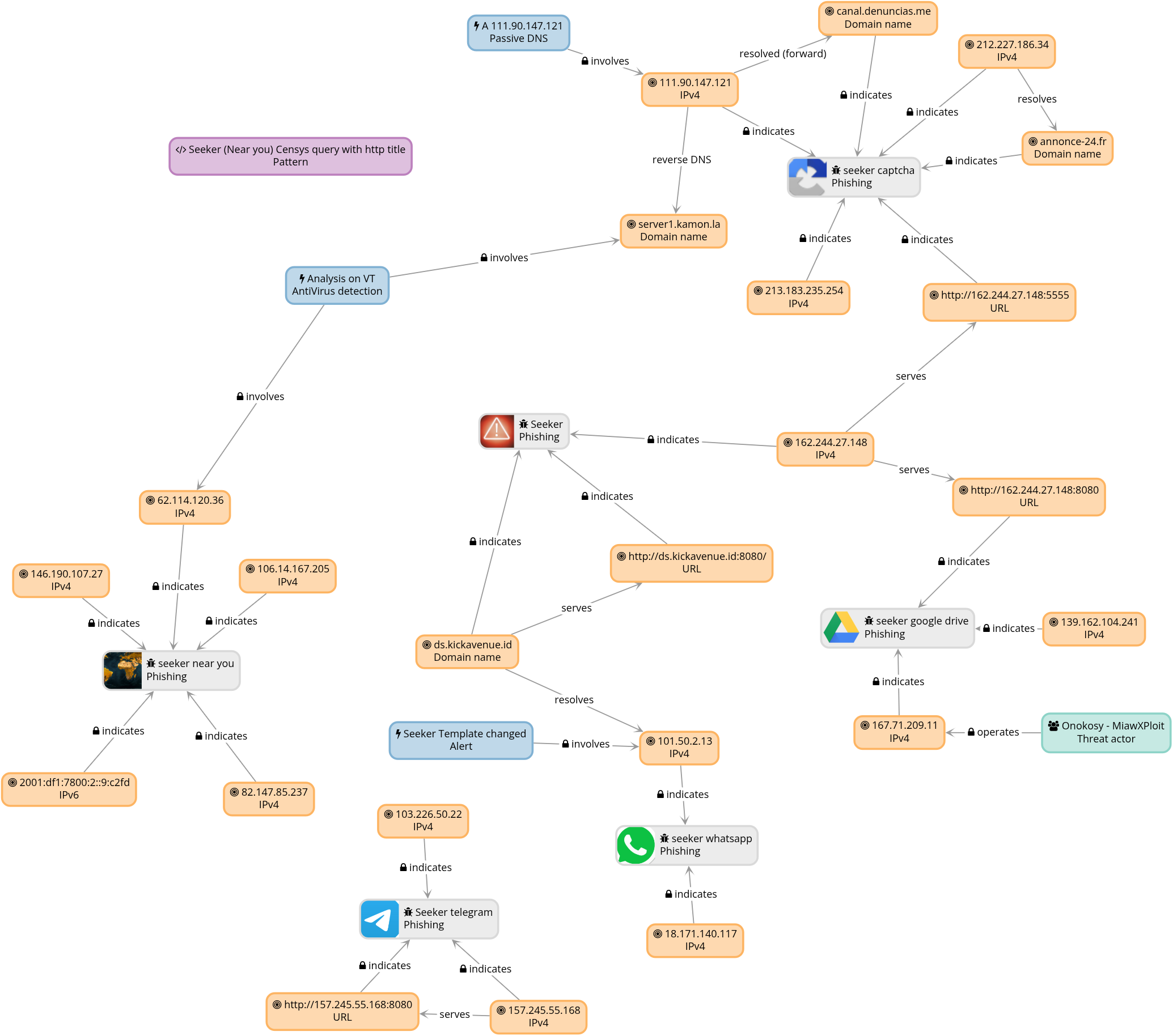
En resumen, aquí vimos lo básico para ordenar hallazgos en Colander; el verdadero valor llega cuando le sumas contexto: revisar históricos de DNS (resoluciones pasadas, cambios de hosting), cotejar con otras bases de threat intel, buscar los observables en VirusTotal u otras fuentes, y cruzar lo que salga (fechas, rutas, certificados, whois, familias) para reforzar hipótesis o descartarlas. Todo ese metadato también vive bien dentro de Colander: como etiquetas (ej. region:latam, template:recaptcha), en descripciones de amenazas/observables, o en comentarios con referencias y notas de confianza. Mientras más trazabilidad y contexto quede pegado al caso, más fácil será pivotear después sin perder el hilo.
Esto es “nuestra forma”, no la única
Colander es potente y viene con ideas muy útiles para equipos de sociedad civil: opera mientras investigas, no sólo como “archivo final”. Hay alternativas como MISP (clásico en threat intel y compartición), con sus propias ventajas; en nuestra experiencia, Colander tiene una curva más amable para llevar casos vivos y luego exportar lo aprendido. También convive bien con otros sistemas si necesitas publicar/consumir feeds. (Si quieres comparar filosofías, mira la página de MISP; acá no nos metemos a fondo).
–[ 0x05 Exportar Feeds y usarlos como IOCs en MVT ]–
Colander tiene una pieza clave para “sacar” lo que encontramos y usarlo: los feeds. Aquí vamos a usar feeds de entidades (no de reglas, eso queda para otro día). Por “entidades” nos referimos a lo que Colander modela en la UI (en inglés): Actors, Artifacts, Devices, Observables, Threats. La idea: exportar Observables y Threats de este caso, bajarlos en STIX2 y apuntar MVT a ese archivo como fuente de IOCs.
No es un curso de Colander: acá vamos a lo operativo mínimo. Quien quiera aprender bien, a la docs de PTS. Este capítulo es “cómo lo hacemos nosotrxs”.
0x05.1 Crear el feed de entidades (Observables + Threats)
-
Feeds → Export entities (menú principal).
-
Qué exportar: marca Observables y Threats (lo demás, off para este experimento).
-
Nombre + descripción: algo que luego reconozcas fácil.
-
Secret: es la clave del feed. Es obligatorio para acceder.
- Puedes tener varios feeds con contenidos distintos y secrets distintos (compartes URL + secret según con quién).
- Puedes rotar el secret cuando quieras (invalida el anterior).
-
TLP / PAP (los dos campos que más confunden al principio):
- TLP (Traffic Light Protocol) define cómo se puede compartir lo exportado.
- PAP (Permissible Actions Protocol) define qué se puede hacer con lo exportado.
- El feed solo incluirá entidades cuyo TLP/PAP sea mayor o igual a lo que selecciones aquí. si seleccionas “WHITE” solo saldrán los whites, si en otro extremo seleccionas los “RED” saldrán todos: los red, yellow, green y white.
- En este experimento dejamos ambos en
WHITE, así no se exportan entidades etiquetadas comoYELLOW(tenemos algunas así porque salieron de un servidor legítimo que estuvo comprometido y preferimos no publicarlas como IOC).
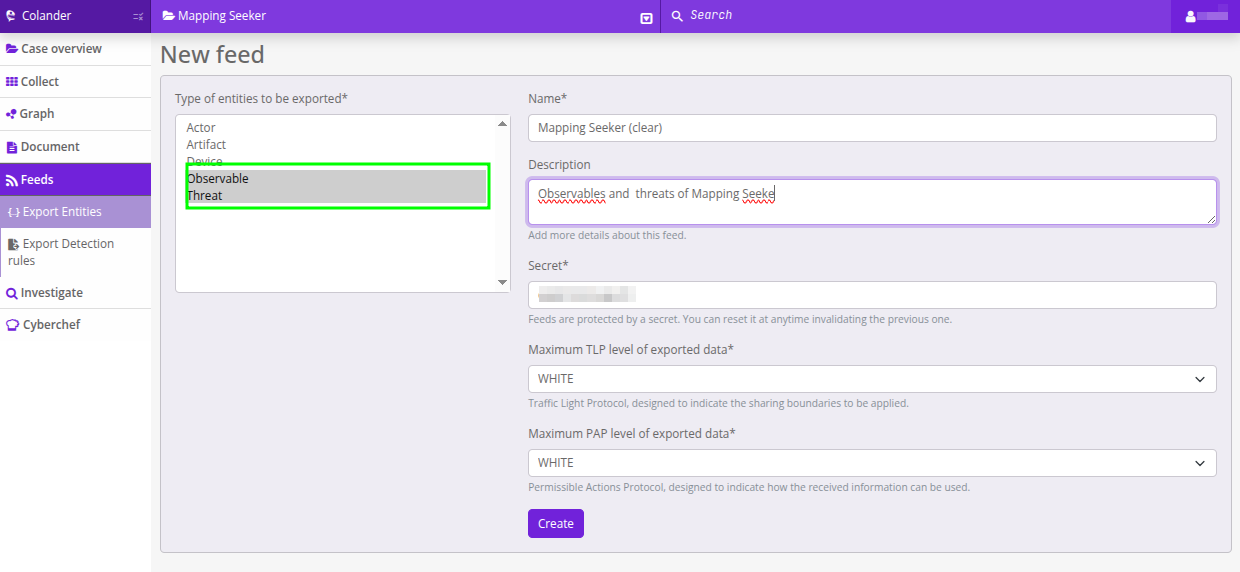
Guarda. Tu feed ya aparece en la lista de Feeds.
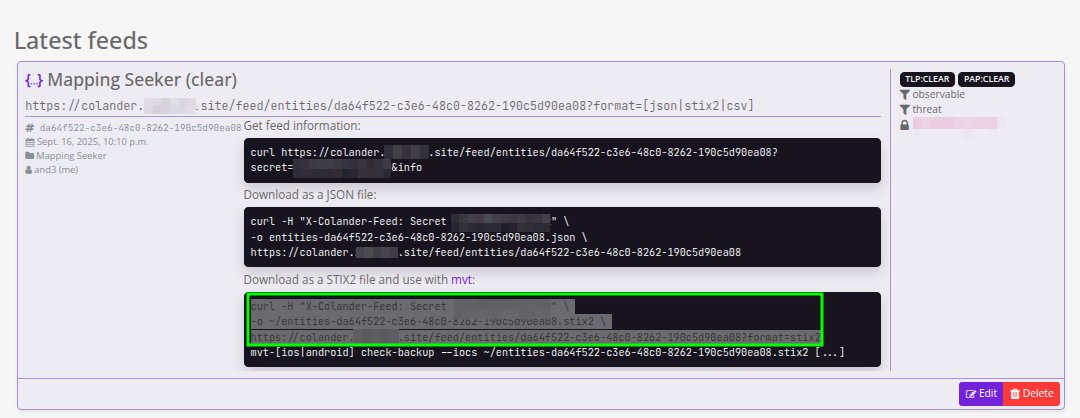
0x05.2 Ver/usar el feed: JSON, STIX2, CSV (y cURL listo)
Al ver la entrada para este feed, verás una url con las opciones para bajar JSON, STIX2 y CSV, y tres recuadros con cURL ya armado. Para nuestro flujo, nos centramos en el que dice:
“Download as a STIX2 file and use with mvt:”
Primero descargamos el feed en formato STIX2.
Ojo con la URL: Colander suele incluir parámetros con caracteres especiales; pon la URL entre comillas o tu shell se va a tropezar.
# Descargar el feed como STIX2
curl -H "X-Colander-Feed: Secret XxxXxXXXxX" \
-o ~/entities-da64f522-c3e6-48c0-8262-190c5d90ea08.stix2 \
"https://colander.somesite.site/feed/entities/da64f522-c3e6-48c0-8262-190c5d90ea08?format=stix2"
0x05.3 Pasar MVT con esos IOCs (androidqf del emulador)
Hemos implantado un SMS con uno de los dominios maliciosos en un emulador de Android, hicimos una extracción con androidqf y vamos a usar esa extracción en esta prueba.
Ahora corremos MVT apuntando a nuestro STIX2 como fuente de IOCs. Dependiendo de tu tipo de extracción, el subcomando puede variar:
mvt-android check-androidqf --iocs ~/entities-da64f522-c3e6-48c0-8262-190c5d90ea08.stix2 ~/androidqf/90eba9d5-95da-429b-8ea0-0e1df58e07dd
Salida esperable : MVT detecta el dominio que documentamos en el caso (p. ej., el dominio en español), y —si tu feed lo incluye en STIX2 con relaciones— verás el indicador etiquetado con el nombre/label de la Threat asociada.

Y con esto completamos el círculo: desde la idea, pasando por la investigación y terminando con la aplicación de los resultados en la vida práctica. ¡Maravilloso! :)
–[ 0x06 Esto es solo el comienzo ]–
Hasta acá, puro calentamiento. Rasguñamos la superficie y ya salieron cosas sabrosas: hosts con más de un señuelo, otros sirviendo malware, algún servidor con 30+ instancias de Seeker corriendo a la vez. El que busca, encuentra. Al principio parece cuesta arriba, pero cuando te pones en la tarea, las piezas encajan, las metodologías se acomodan y —como nos gusta decir—** no aprendemos a hackear: hackeamos para aprender**.
En ZoqueLabs esto es lo nuestro: experimentar, fallar rápido, iterar y destilar prácticas que sirvan a la inteligencia de amenazas. Este experimento sigue abierto; si te atoras, si quieres compartir pistas, si te pica la curiosidad: escríbenos. Somos un nodo en un ecosistema que necesita más nodos —más ojos sobre las amenazas— para detectarlas a tiempo, actuar y documentar.
El repositorio con los Feeds de este experimento se puede encontrar aquí: https://github.com/ZoqueLabs/mapping-seeker-files
Nos vemos en la próxima cacería. Trae café, logs y ganas de romperte la cabeza con cariño.